Zoom sur Treasure Data – Benchmark CDP

Vous allez découvrir dans cette publication l’essentiel de ce qu’il faut savoir sur la CDP Treasure Data :
- Executive Summary
- Le positionnement de l’éditeur
- Le positionnement de la CDP Treasure Data
- Les points forts de cette plateforme
- A quels types d’entreprises elle s’adresse
- Un tour d’horizon du périmètre fonctionnel de la Customer Data Platform Treasure Data, illustré par des captures d’écran
CustUp est spécialisée dans la structuration et la mise en œuvre de la Relation Clients via la Data et les outils de l’écosystème CRM. Les CDP jouent un rôle pivot et croissant. C’est la raison qui nous a décidés à proposer à nos lecteurs un Benchmark des CDP.
Page mise à jour le 19 octobre 2023
Executive Summary
- Notre perception de l’ADN de l’éditeur : un éditeur à l’origine fortement implanté au Japon en cours de conquête des marchés américain et européen depuis son rachat par le fonds Softbank. Un acteur issu du Big Data (Data Lake) ayant pivoté pour proposer une Customer Data Platform.
- Le positionnement de Treasure Data : Une CDP orientée Data Management proposant des fonctionnalités très avancées en matière de connexion, unification, préparation et segmentation des données : une CDP modulaire vendue sous différentes déclinaisons selon les usages (marketing, service, sales).
- Les points forts de la Customer Data Platform Treasure Data : une très grande flexibilité qui donne notamment la capacité à intégrer n’importe quels types de données et de s’adapter à vos futurs scénarios d’utilisation ; une très grande profondeur fonctionnelle ; une interface adaptée à chaque profil utilisateur (IT/Data et métier) ; une excellente gestion des environnements complexes (multi-filiales, pays…) ; une gestion avancée des droits et permissions ; + de 50 algorithmes prédictifs sur l’étagère ; une capacité à gérer de très grands volumes de données.
- A qui s’adresse Treasure Data ? Aux ETI et grandes entreprises ayant déjà une bonne maturité data. Treasure Data s’adresse à tous les secteurs d’activité.
CustUp est indépendant des éditeurs
Précision importante : CustUp est indépendant des éditeurs. Nous ne percevons aucune rémunération directe ou indirecte de leur part. Techno-agnostiques, nous recommandons à nos clients les solutions logicielles les plus en adéquation avec leurs ambitions et besoins.
Lancée au Japon en 2011, Treasure Data représente aujourd’hui 90% du marché de la CDP au Japon. Treasure Data a été racheté par le fonds d’investissement Softbank et cible désormais les marchés américains et européens. Le siège social de Treasure Data est installé à Mountain View (Californie).
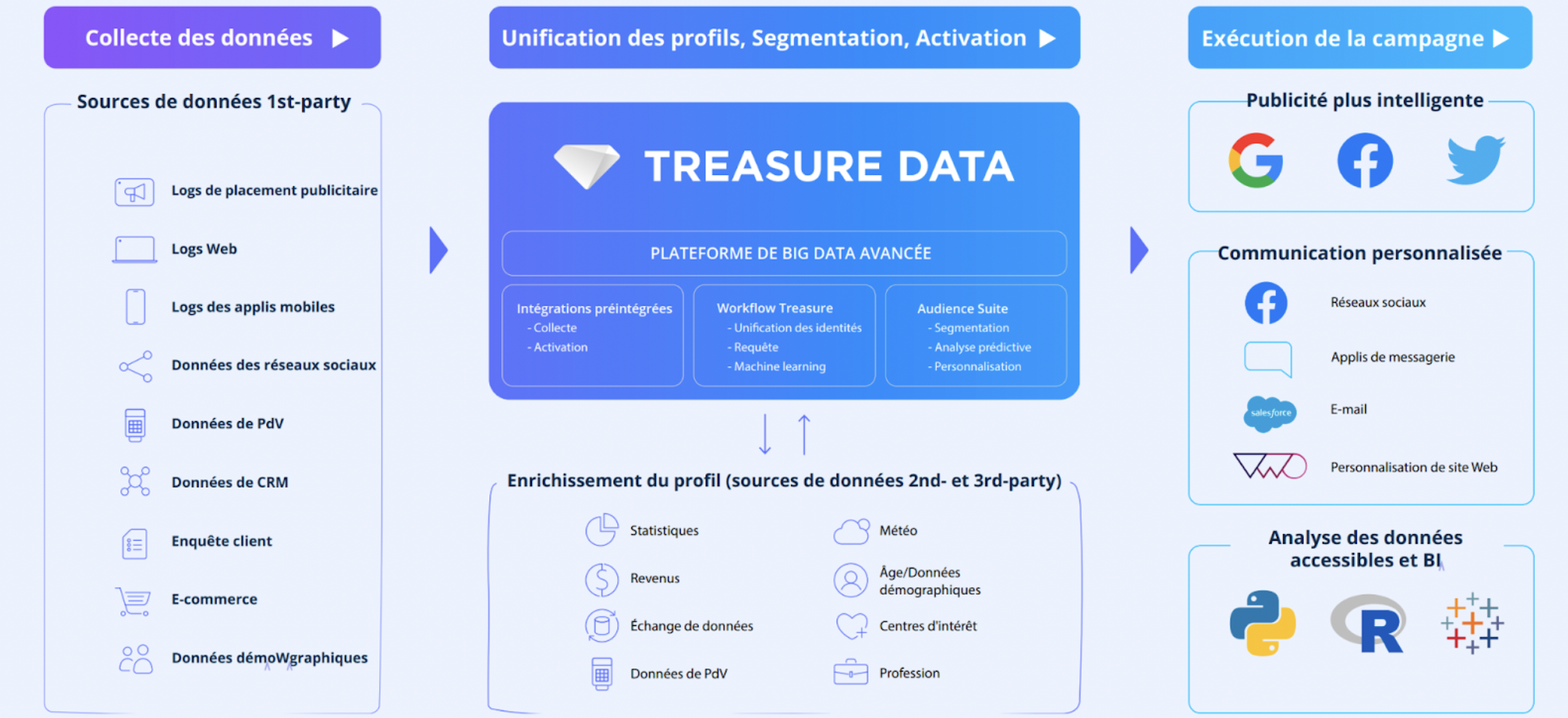
Treasure Data était historiquement positionné comme une plateforme de big data (Data Lake) avant de pivoter pour devenir une Customer Data Platform. Cette origine se traduit aujourd’hui encore dans la capacité de la plateforme à gérer de très gros volumes de données.
- Treasure Data est une CDP orientée Data Management, dont les fonctionnalités les plus puissantes sont celles ayant trait à la connexion des données (capacités très avancées d’intégration), au nettoyage, à la normalisation et unification des données, à la création d’une vision 360 et à la segmentation.
- Treasure Data n’a pas vocation à remplacer les outils d’activation et de Business Intelligence de l’entreprise, même si l’éditeur propose un Journey Builder (Customer Journey Orchestration) vendu séparément. Treasure Data se concentre sur l’unification et l’enrichissement des données et sur la création d’audiences/segments avancées, de scores basés sur des modèles prédictifs, ainsi que leur analyse.
- Treasure Data propose plusieurs déclinaisons de la Customer Data Platform adaptées aux cas d’usage cibles :
- CDP for Marketing.
- CDP for Services.
- CDP for Sales.
- Treasure Data est une plateforme modulaire. Le client n’active que les fonctionnalités dont il a besoin. Si, par exemple, le client possède sa propre solution de Data visualisation / Business Intelligence, le module “Treasure Data Insights” peut ne pas être activé.
- Le modèle de données n’est pas imposé (schemaless). En revanche, de nombreuses fonctionnalités sont préparamétrées pour faire gagner du temps au client – que ce soit au niveau de la gestion de la qualité des données, de la normalisation, de la segmentation, du scoring. Tous ces pré-paramétrages sont 100% personnalisables.
Fonctionnement de la Customer Data Platform Treasure Data.
- La capacité à intégrer n’importe quels types de données, online et offline, structurées, semi-structurées, non structurées. Treasure Data propose de nombreuses possibilités d’intégrations : connecteurs, APIs, webhooks, tags, SDK, pixels, fichiers plats…
- Comme n’y a pas de modèle de données prédéfini et toutes les données peuvent être intégrées dans la plateforme sans qu’aucun prétraitement ne soit nécessaire. Cela simplifie la mise en place de l’intégration et améliore la vitesse de la mise en œuvre globale. Avec des centaines de connecteurs de données prêts à l’emploi, la solution permet d’activer des premiers cas d’usage en 8 à 10 semaines.
- Une très grande profondeur fonctionnelle à toutes les étapes de traitement des données : unification déterministe et probabiliste, enrichissement des données par machine learning (next best product, horaire/canal préféré du client…), segmentations avancées (basées sur des données de profil, comportementales et des scores prédictifs).
- Une interface adaptée et bien différenciée pour les utilisateurs IT d’une part (SQL…) et marketing d’autre part (interfaces user-friendly, no code).
- Conséquence du point précédent, Treasure Data favorise la collaboration des équipes IT et métier. Les étapes amont sont principalement gérées par l’IT : connexion des données, unification, enrichissement. Les étapes suivantes sont gérées en autonomie par le métier, via des interfaces no code : création des segments, des audiences, vue client 360, configuration des flux d’export.

Une plateforme pour les équipes IT/Data et pour les équipes métier.
- Treasure Data gère très bien les environnements complexes, multipays, multi-filiales, multi-devises…Treasure accompagne de grands comptes dans le déploiement de projets CDP internationaux (tout en s’adressant également à des entreprises de moindre taille (ETI)).
- Une gestion avancée des droits, accès et permissions qui rend possible une bonne gouvernance des données. Les droits sont définis par statuts d’utilisateurs (owner, admin, utilisateurs), par typologie de données, par BU/pays, par attribut, par fonctionnalité.
- Plus de 50 algorithmes sur l’étagère pour unifier et enrichir les données.
- La capacité à gérer des volumes très importants de données, ce qui s’explique par le positionnement historique de l’éditeur (Big Data). Ceci apporte une très grande flexibilité qui permet de réaliser des projets rapidement (8 à 12 semaines en moyenne).

Treasure Data s’adresse principalement aux ETI et aux grandes entreprises ayant un bon niveau de maturité data et des cas d’usage complexes (acquisition, fidélisation, optimisation, ROI marketing, campagnes temps-réel et omnicanal).
Même si Treasure Data compte de nombreuses références dans le secteur de l’automobile (Yamaha, Honda, Subaru, Volvo), l’éditeur n’a pas de spécialisation métier et travaille avec des entreprises des pgc, du retail, des médias, de la finance… La CDP s’adresse aux entreprises de tous les secteurs, B2C et B2B.
Treasure Data est adapté aux entreprises ayant à partir de 1 million de profils (clients/prospects uniques de la marque) dédupliqués (en B2C).
| Périmètre fonctionnel | Description |
|---|---|
| Connexions | - Un ETL maison que Treasure Data utilise pour créer des connecteurs natifs : plus de 1000 disponibles. - Tous types de données peuvent être intégrés : données structurées, semi-structurées, non structurées. - Un tag JavaScript pour récupérer les événements web. - Des SDKs mobiles (Android et iOS) et des SDKs d'applications. - Des pixels pour tracker l'engagement publicitaire. - Possibilité de créer des scripts custom en Python ou Spark. - Un IoT device agent pour récupérer les données des objets connectés. - Intégration possible en batch (CSV, JSON). - Un éditeur de workflows d'intégration. |
| Personnalisation du modèle de données | - Aucun modèle imposé. Treasure Data peut accueillir n'importe quel modèle de données. - Des briques de modèles de données sur l'étagère sont proposées. - Les données sont organisées dans des Master Segments qui permettent de créer plusieurs vues clients 360 (par filiale, par pays...). |
| Normalisation & déduplication | - Treasure Data intègre nativement de nombreuses fonctionnalités/workflows de nettoyage et normalisation des données. - Treasure Data peut réconcilier tous types d'IDs. - Les règles de déduplication sont éditées en SQL (pas d'interface no code). - L'unification et la déduplication des données sont gérées par l'équipe IT/data. - Treasure Data gère le matching déterministe et probabiliste. |
| Traitements externes de la donnée | - Treasure Data propose de nombreux connecteurs avec des solutions de nettoyage, standardisation et enrichissement des données : LiveRamp, Allant, Acxiom, Mapbox, Tapad, Neustar, Experian... |
| Vue client | - Vues clients personnalisables. - 1 vue profil créée pour chaque contact, inconnu ou connu. - Réconciliation des données anonymes et identifiées lorsque le contact s'identifie. |
| Reporting & Analytics | - De nombreux tableaux de bord proposés dans Treasure Insights : état de la base, segmentation, performance des actions marketing-ventes... - Un éditeur de tableaux de bord sur-mesure. - Intégration des données de la CDP dans des outils de reporting tiers via des connecteurs natifs vers les principales solutions de BI : Tableau, PowerBi, Qlik... |
| Segmentation & scoring | - Un éditeur d'audiences no-code, conçu pour être utilisé par le métier. - Tous les attributs, événements mais également scores peuvent être utilisés pour créer des segments. - Possibilité d'utiliser SQL pour créer des segments avancés. - 50 algorithmes prédictifs sur l'étagère. - Treasure Data peut accueillir des algorithmes construits en dehors de la plateforme. |
| Orchestration & activation | - Treasure Data propose près de 200 connecteurs avec des solutions d'activation et de BI : CRM, marketing automation, ERPs, ecommerce, media, service client, data visualisation, personnalisation web, A/B Testing... - La création des flux d'export avec la fréquence de votre choix (vues clients, audiences) s'effectue depuis une interface guidée et no code. - Treasure Data propose un Journey Builder vendu en option. - Treasure Data a également la capacité d'activer en temps réel grâce à une API de personnalisation en temps réel, des webhooks, des API de postback, par le biais de divers SDK d'application et d'une API REST. Une fois ces activations publicitaires effectuées, Treasure Data est en mesure de réinjecter les résultats de ces campagnes dans la plateforme et le cycle recommence. |
| Stockage & hébergement | - Full SaaS. - Données hébergées sur des serveurs AWS, au choix : USA, Japon, Corée du Sud, Union européenne (Francfort). |
| Projet | - Les projets sont pilotées soit par l'éditeur, par un partenaire, soit en binôme (éditeur + partenaire). - Treasure Data a noué des partenariats avec de nombreux cabinets de conseil, intégrateurs et agences, notamment en France. - Seuls les partenaires certifiés peuvent intervenir sur des projets de déploiement de la CDP Treasure Data. |
Si vous êtes en phase de réflexion sur le choix de votre Customer Data Platform et que vous cherchez à mieux connaître les acteurs du marché, nous vous invitons à découvrir les autres plateformes présentes dans notre Panorama CDP, notamment :
Treasure Data utilise un ELT pour connecter les données du SI Client de l’entreprise à la Customer Data Platform. Cet ELT est maintenu par l’éditeur et permet des ingestions temps réel. Plus de 1 000 intégrations natives ont été développés à partir de lui. Les équipes Treasure Data peuvent créer de nouveaux connecteurs, sur demande, dans un délai de 6 à 8 semaines.

Les connecteurs natifs proposés par Treasure Data.
Les sources de données peuvent également être connectées par APIs ou par SDKs pour les données web et mobile (Android et iOS). Treasure Data utilise un tag JavaScript (cookie based) pour récupérer les données comportementales web. Ce tag est intégré sur les sites internet et peut coexister avec n’importe quel Tag Management System.
Treasure Data utilise également :
- Des pixels pour tracker l’engagement des clients vis-à-vis des publicités.
- Une API postback pour envoyer des données à la CDP via des webhooks.
- Python ou Spark pour créer des scripts d’import custom.
- Un Server-side agent ou un IoT device agent pour streamer les données issues de weblogs, d’ad logs, d’access logs, des objets connectés.
Treasure Data prend également en charge une variété de SDK d’applications (pour Python, Ruby, Java, Node et Go) qui peuvent être utilisés pour interagir avec la CDP Treasure Data.
L’intégration en batch, par import de fichiers plats (CSV ou JSON), est également ouverte, avec la possibilité de déterminer la fréquence d’import : heure, journée, hebdomadaire.
Treasure Data est construit sur une architecture Big Data qui permet d’intégrer aussi bien les données structurées, semi-structurées et non-structurées (JSON, XML…).
Les capacités d’intégration des données sont remarquables. Treasure Data offre de multiples modalités d’intégration qui permettent de connecter n’importe quel type de données : données CRM, données web, données mobile, données des objets connectées, données du service client, données d’applications, données POS, données ecommerce, logs, données de consentement…
Treasure Data Workflows permet de scénariser l’import des données (mais également la préparation des données et leur synchronisation dans les outils de destination).
Les données ingérées dans Treasure Data peuvent être organisées dans une ou plusieurs bases de données (dans le cas de groupes ayant plusieurs filiales, pays, ou d’organisations ayant plusieurs business units).
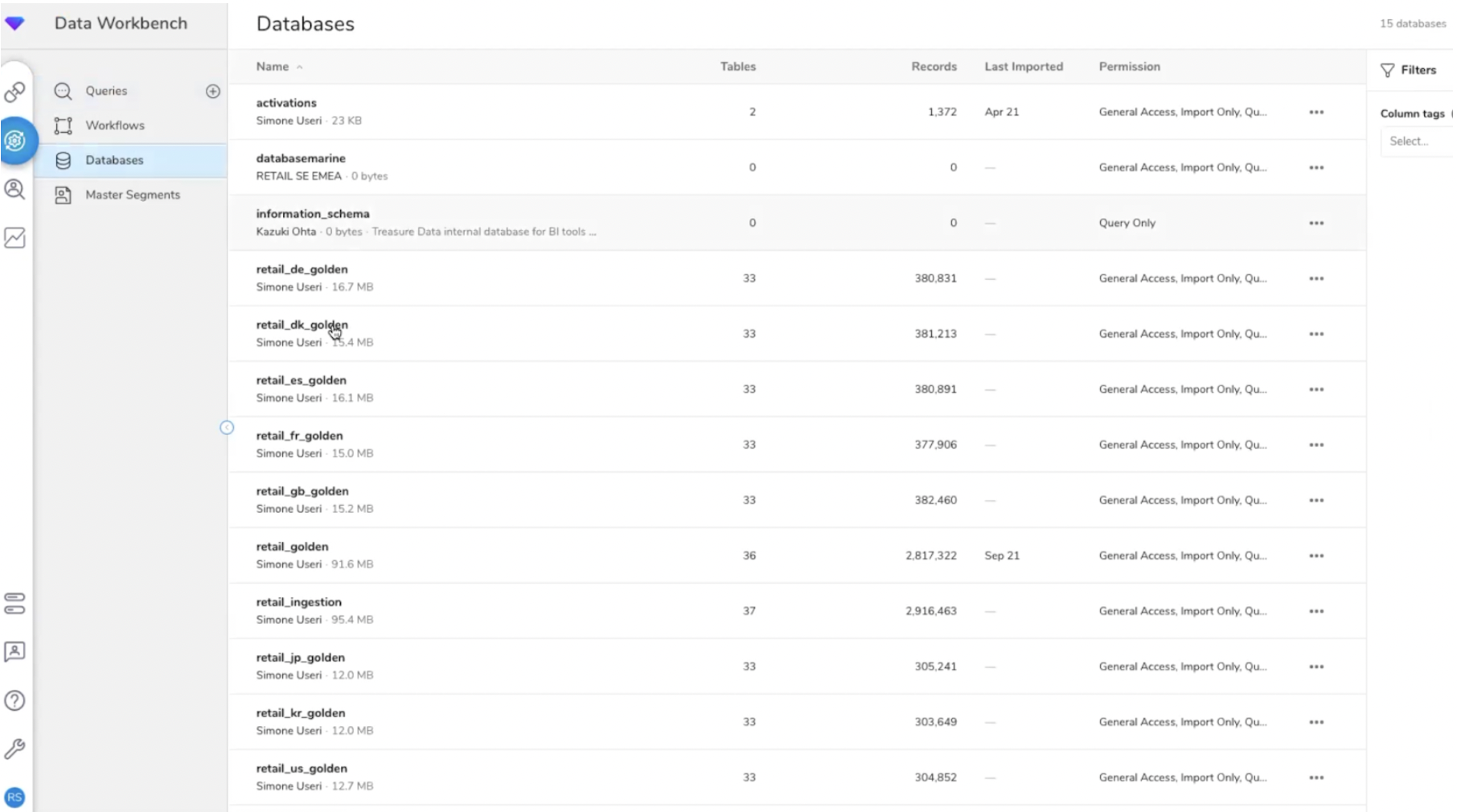
Les données connectées à la CDP sont organisées dans une ou plusieurs bases de données.
Préparation & Unification des Données
Personnalisation du modèle de données
Treasure Data est “schemaless”. La CDP n’impose aucun modèle de données. Cela signifie qu’il est possible de stocker n’importe quel type de données (structurées, semi-structurées ou non-structurées) dans un modèle de données construit sur mesure.
Treasure Data propose des modèles de données standards (mais personnalisables) conçus pour certains secteurs d’activité ou certains types de données. Par exemple, Treasure Data propose un modèle de données pour les données web (pages vues et événements) et un modèle pour les données mobile (Android et iOS). Ces briques de modèles de données visent à faire gagner du temps aux clients et sont totalement paramétrables.
Le modèle de données est constitué de plusieurs “Master Segments” constitués de différentes tables organisant les attributs et les événements clients. Chaque Master Segment contient une Master Table définie par un ID unique (nom, prénom, email, ID cookie…), une table Attributs (âge, genre, revenus, centres d’intérêt…) et une table événements (pages vues, etc.). Cette organisation du modèle de données en X Master Segments permet de créer plusieurs vues clients 360 (par pays, filiale…).
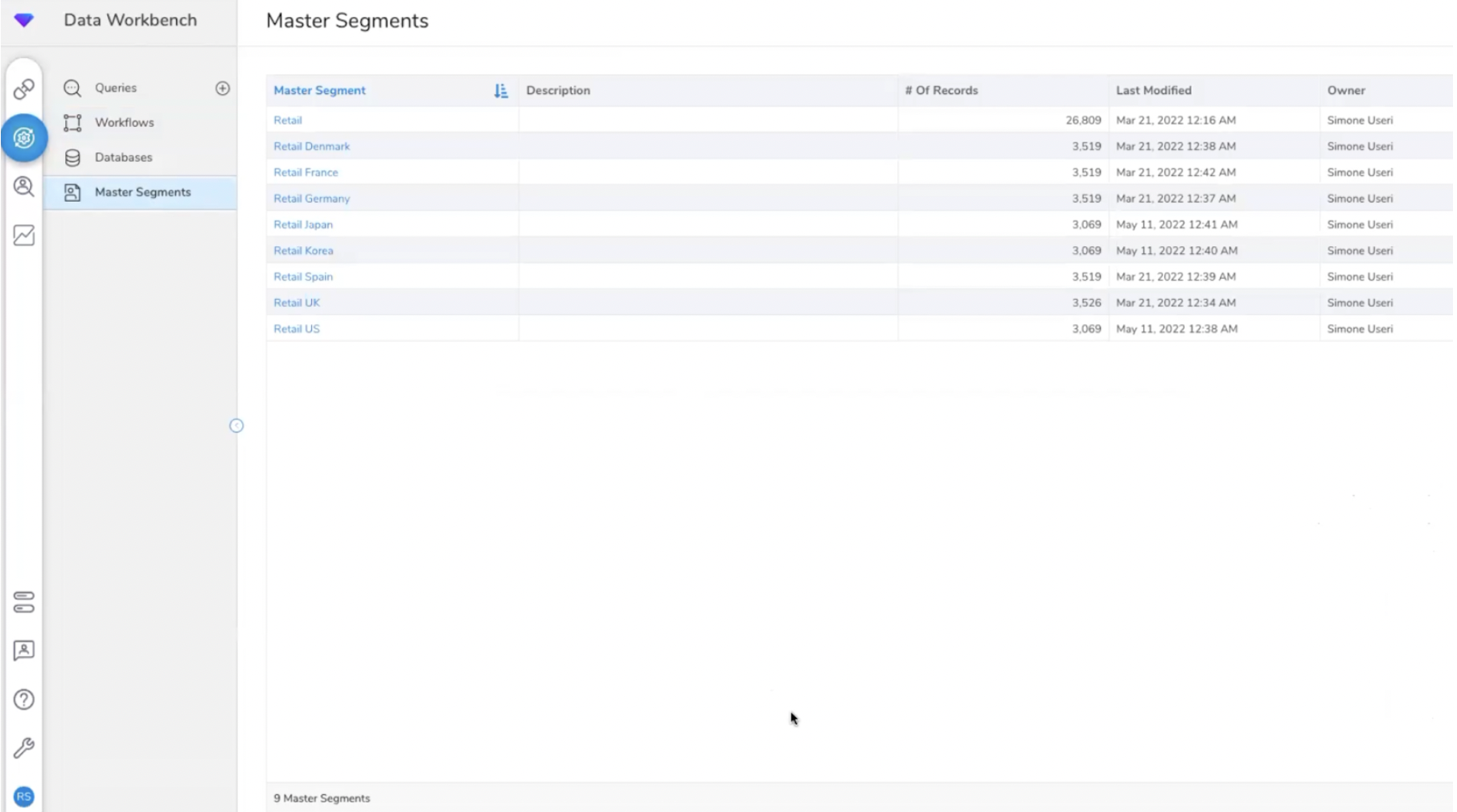
Le modèle de données s’organise en X Master Segments.
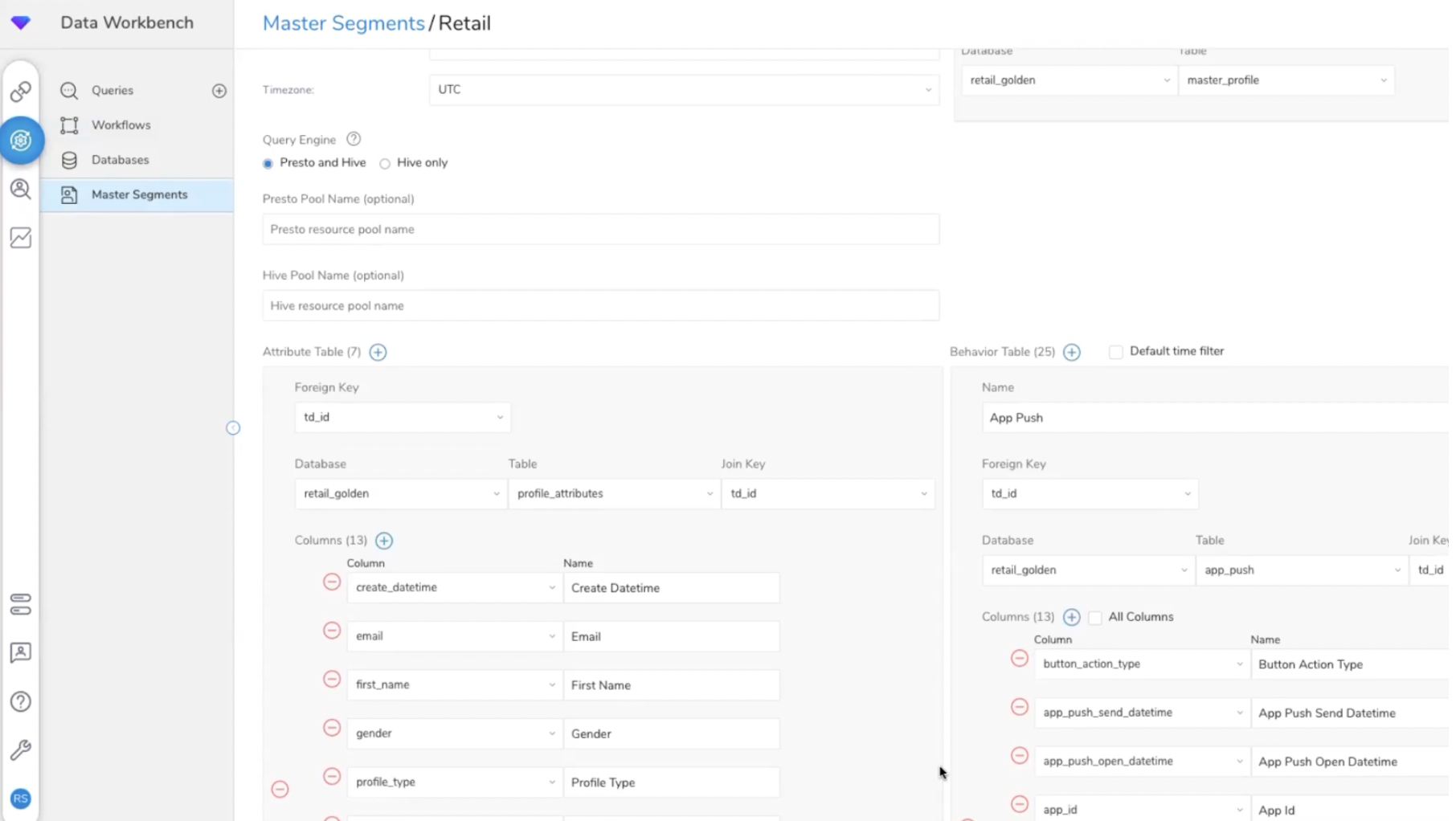
La configuration des tables d’un Master Segment (1).
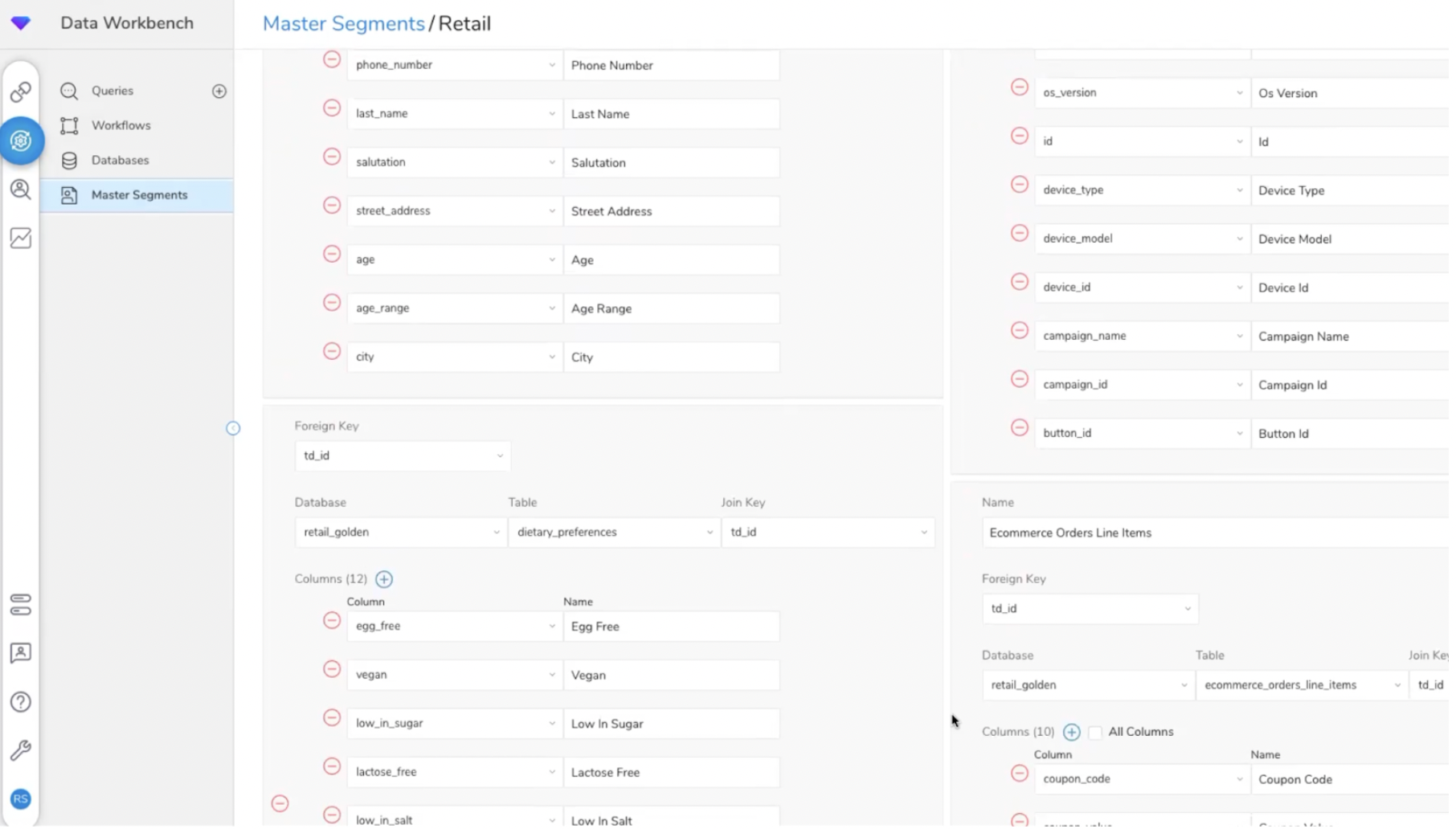
La configuration des tables d’un Master Segment (2).
Nettoyage, normalisation & déduplication
Treasure Data intègre nativement des fonctions de nettoyage et de vérification des données. Il est possible de séquencer, planifier et exécuter des règles de nettoyage des données standards ou personnalisées. Ces règles sont paramétrées dans la section Workflow. Il est possible de définir un système d’alertes pour être averti en cas de données non conformes. Les données nettoyées sont intégrées dans un nouveau layer, ce qui permet de conserver les données brutes.
La CDP Treasure Data gère la normalisation, la déduplication, l’unification autour d’un ID unique de toutes les données ingérées dans la plateforme. Treasure Data gère tous les types d’ID : email, cookie, téléphone, nom + prénom + adresse postale, nom + prénom + date de naissance, numéro d’abonné…Un ID unique est créé à partir de tous les IDs clients, avec conservation des ID tiers.
Les règles de déduplication des données sont paramétrées par l’équipe data/IT, qui peut utiliser des templates de règles de déduplication sur l’étagère proposées par l’éditeur. Treasure Data ne propose pas d’interface no code de configuration des règles de déduplication. Ces règles sont éditées en SQL.
Treasure Data gère aussi bien le matching déterministe que le matching probabiliste. Il est possible d’utiliser le Fuzzy Matching. Il est possible d’utiliser des algorithmes comme Soundex, Hamming Distance ou Levenshtein Distance pour calculer des scores de similarité entre deux chaînes et de fusionner les enregistrements lorsque le seuil de score est atteint.

Treasure Data gère le matching probabiliste.
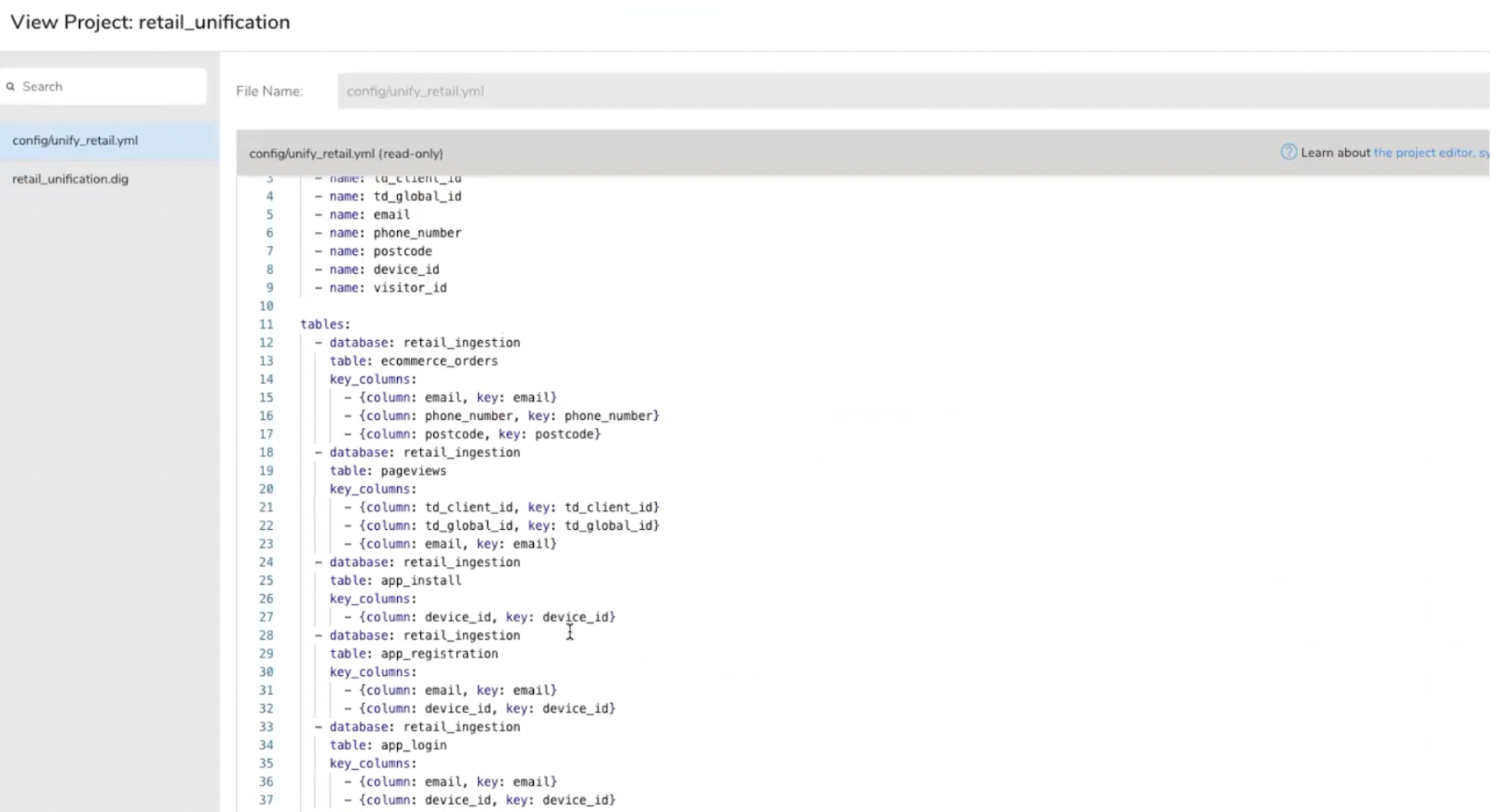
Configuration de l’unification des données.
Traitements externes de la Donnée
Treasure Data propose de nombreux connecteurs sur l’étagère avec des services ou outils de Data Quality, de standardisation ou d’enrichissement des données comme LiveRamp, Allant, Acxiom, Mapbox, Tapad, Neustar, Experian, Equifax…Ces intégrations viennent enrichir les fonctionnalités déjà avancées proposées nativement par Treasure Data.
Vue Client
Les données ingérées et préparées dans Treasure Data alimentent des vues clients 360 personnalisables. Ces vues clients permettent de visualiser l’ensemble des données se rattachant à un client…ou à un contact.
La vue profil est en effet créée dès qu’un cookie first party ID est généré, avant l’identification de l’individu. Une fois le client identifié, la plateforme réconcilie les données anonymes (liées à l’ID cookie) et les données identifiées (CRM, transactionnelles…).

La vue client 360 est construite à partir de toutes les données online/offline ingérées dans la CDP.
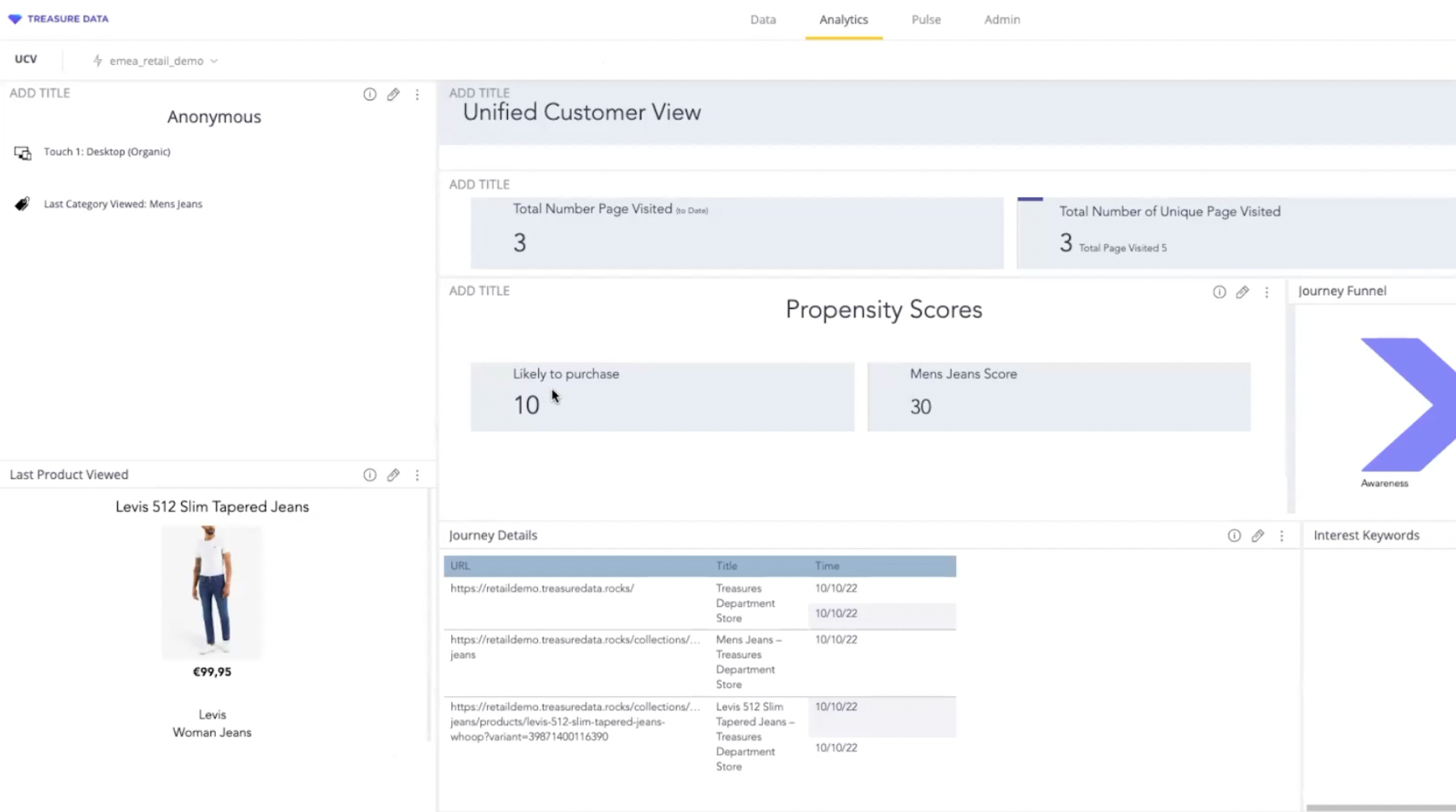
Vue profil 360. Le contact, en l’occurrence, est encore anonyme.
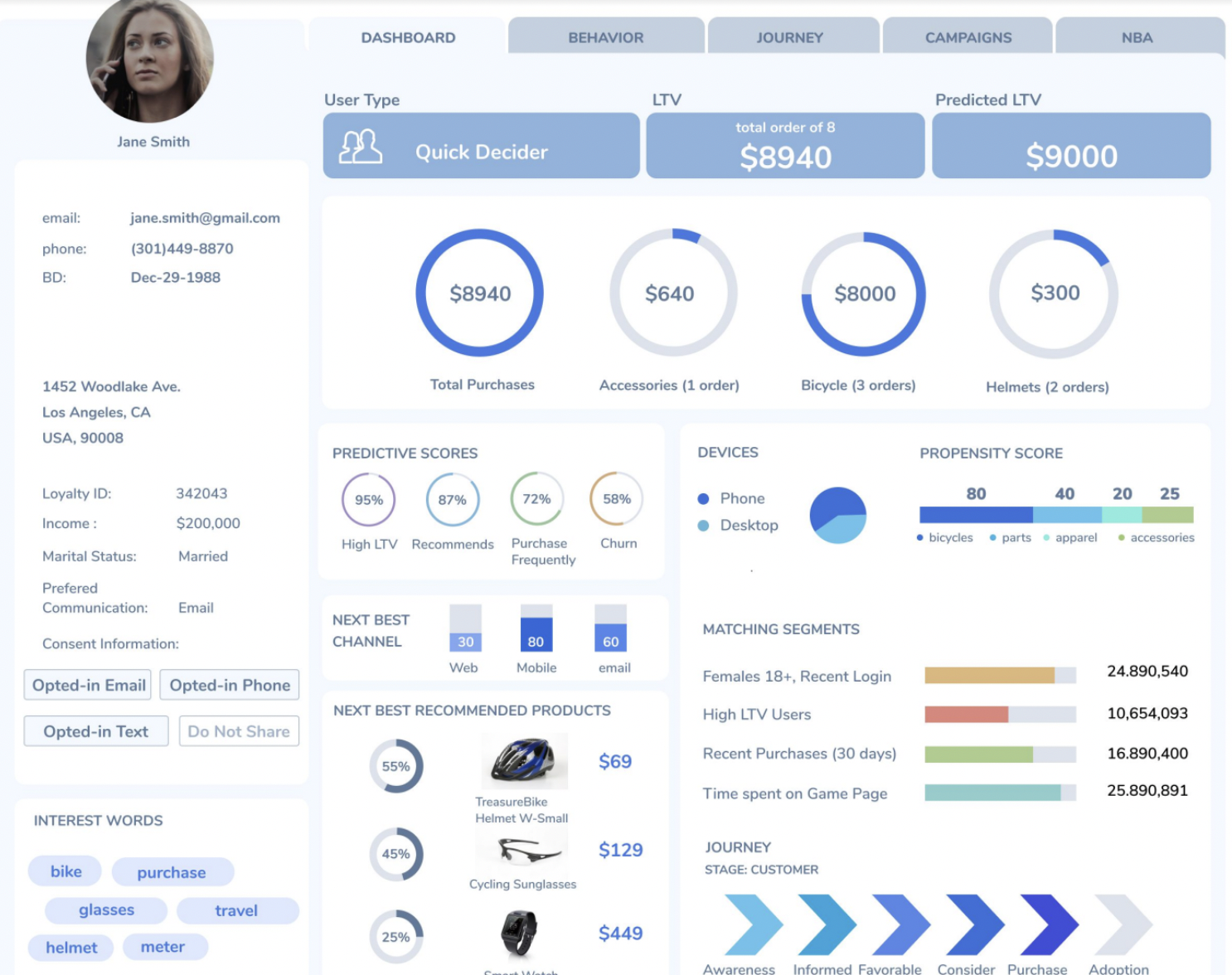
Vue profil 360 d’un client identifié.
Reporting & Analytics
Treasure Data propose plusieurs tableaux de bord sur l’étagère via le module Treasure Insights :
- ID resolution.
- Audience Insight.
- Web Analytics.
- Time Serie Forecast.
- Data Profiling.
- …/…
Les dashboards sur l’étagère couvrent les principaux besoins : vue générale, état de la base, comportement client, parcours clients, performance des campagnes…
Treasure Data propose par ailleurs un éditeur de tableaux de bord (no code, utilisable par les équipes métiers) permettant de créer des reportings sur-mesure. Les données unifiées et les vues 360 peuvent bien entendu être exportées dans des systèmes de reporting tiers.
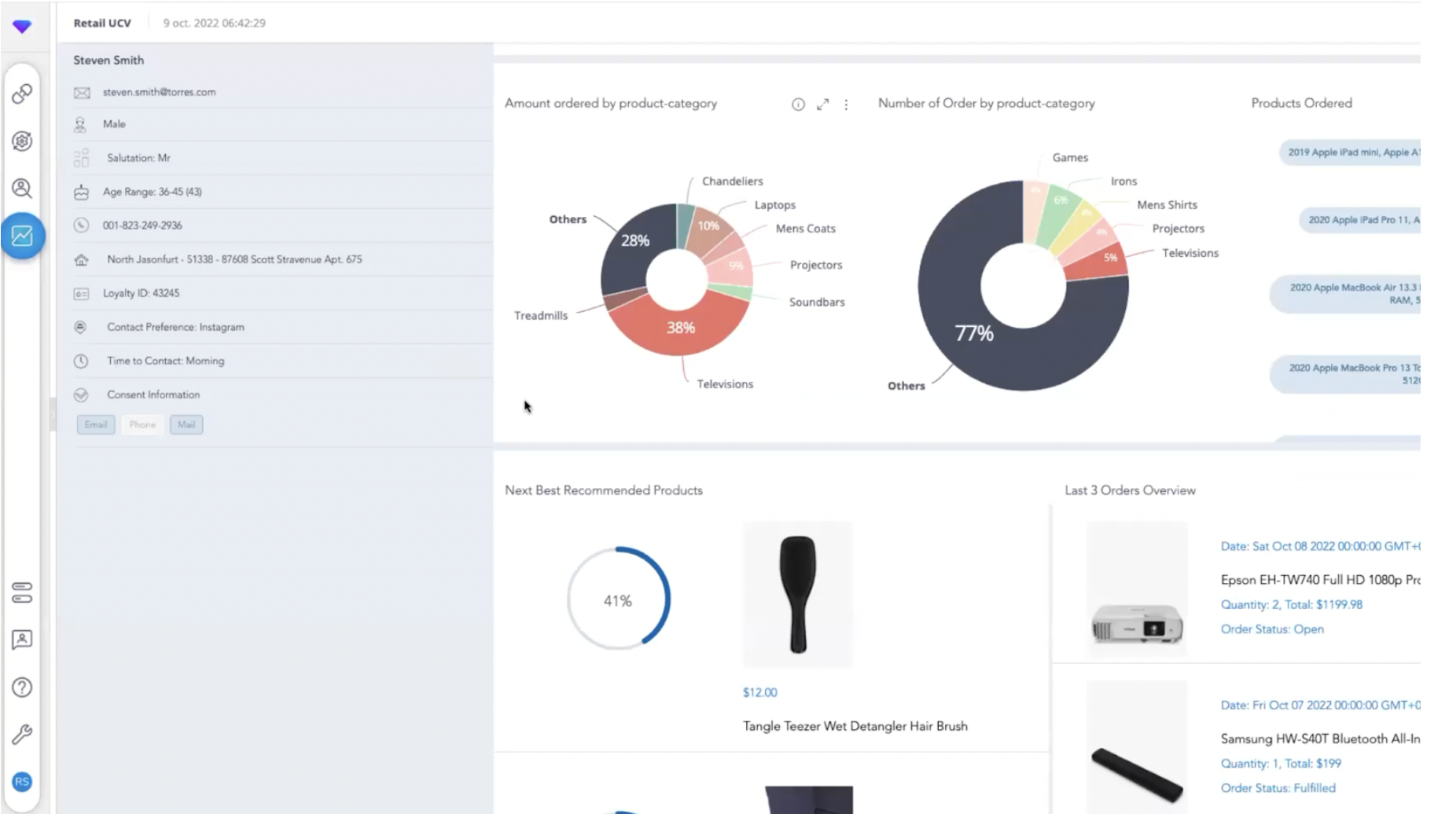
Un exemple de dashboard sur l’étagère (mais personnalisable) proposé par Treasure Data.
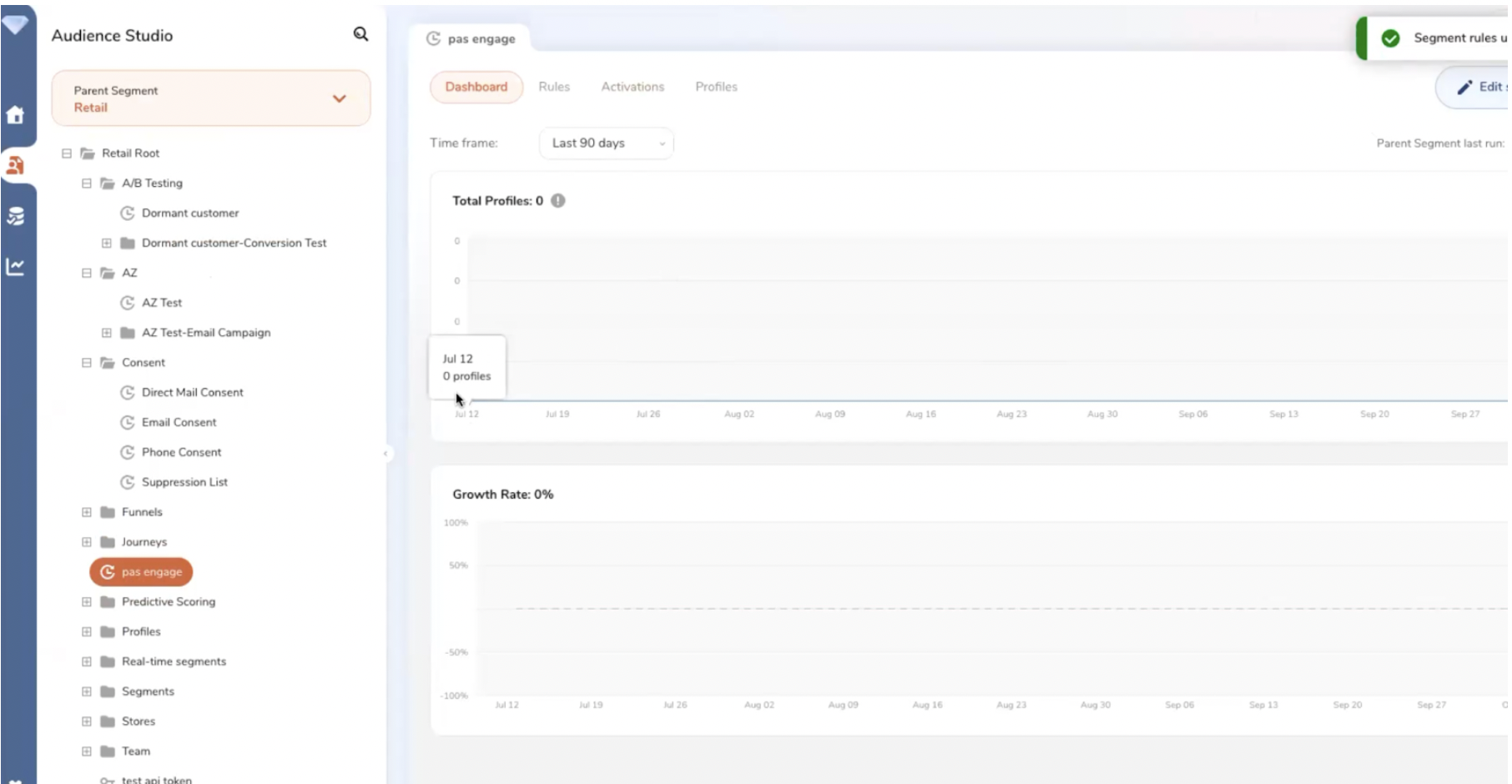
Un tableau de bord pour suivre la segmentation client.
Segmentation & Scoring
L’éditeur d’audiences (Audience Studio) proposé par Treasure Data est no code. Il est conçu pour être utilisé par les équipes métier.
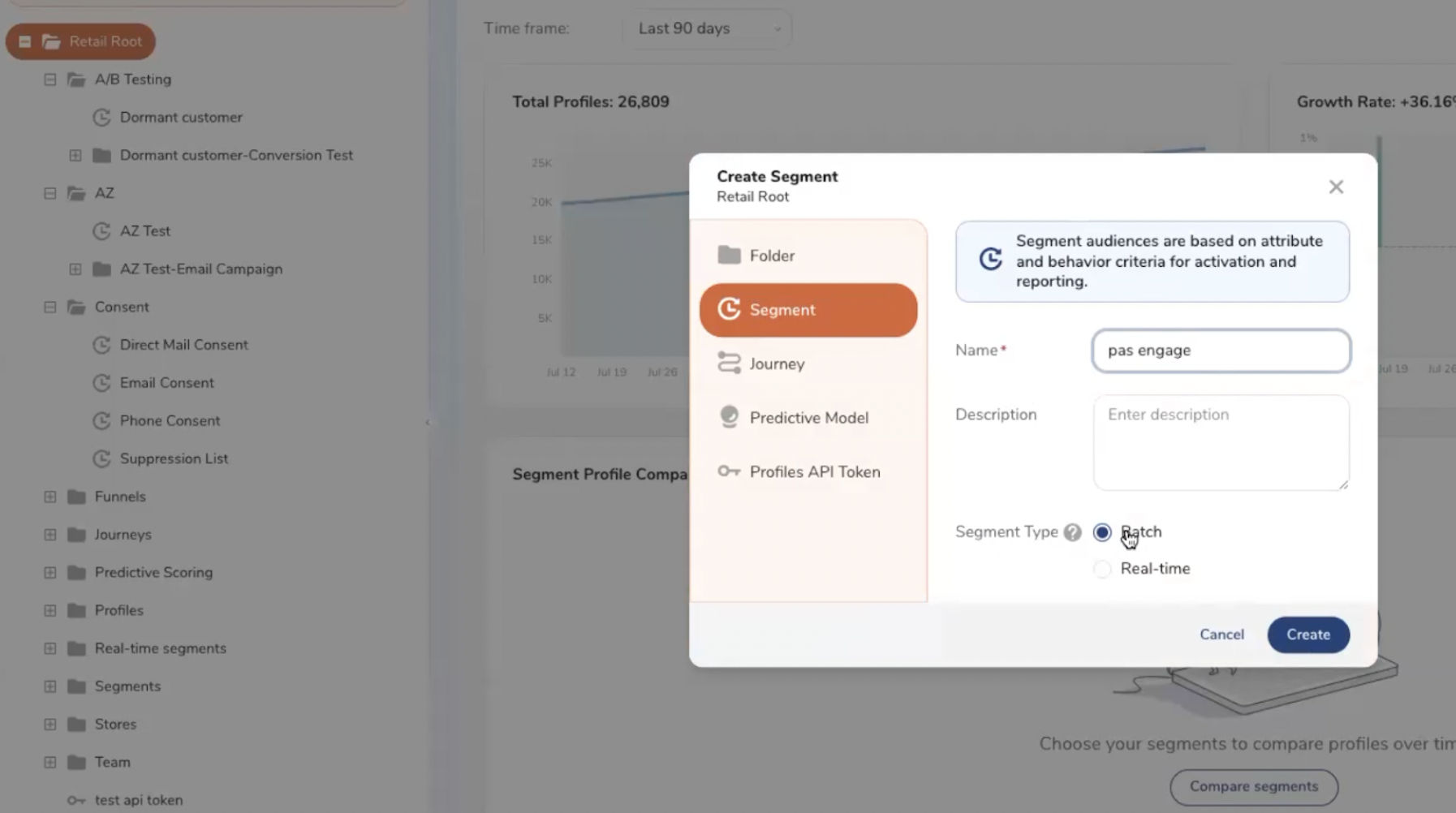
La création d’un nouveau segment (nouvelle audience).
Les segments sont créés via le paramétrage de règles et de conditions. Les règles sont combinables entre elles. Treasure Data gère les opérateurs classiques : AND, OR, AND NOT, CUSTOM…
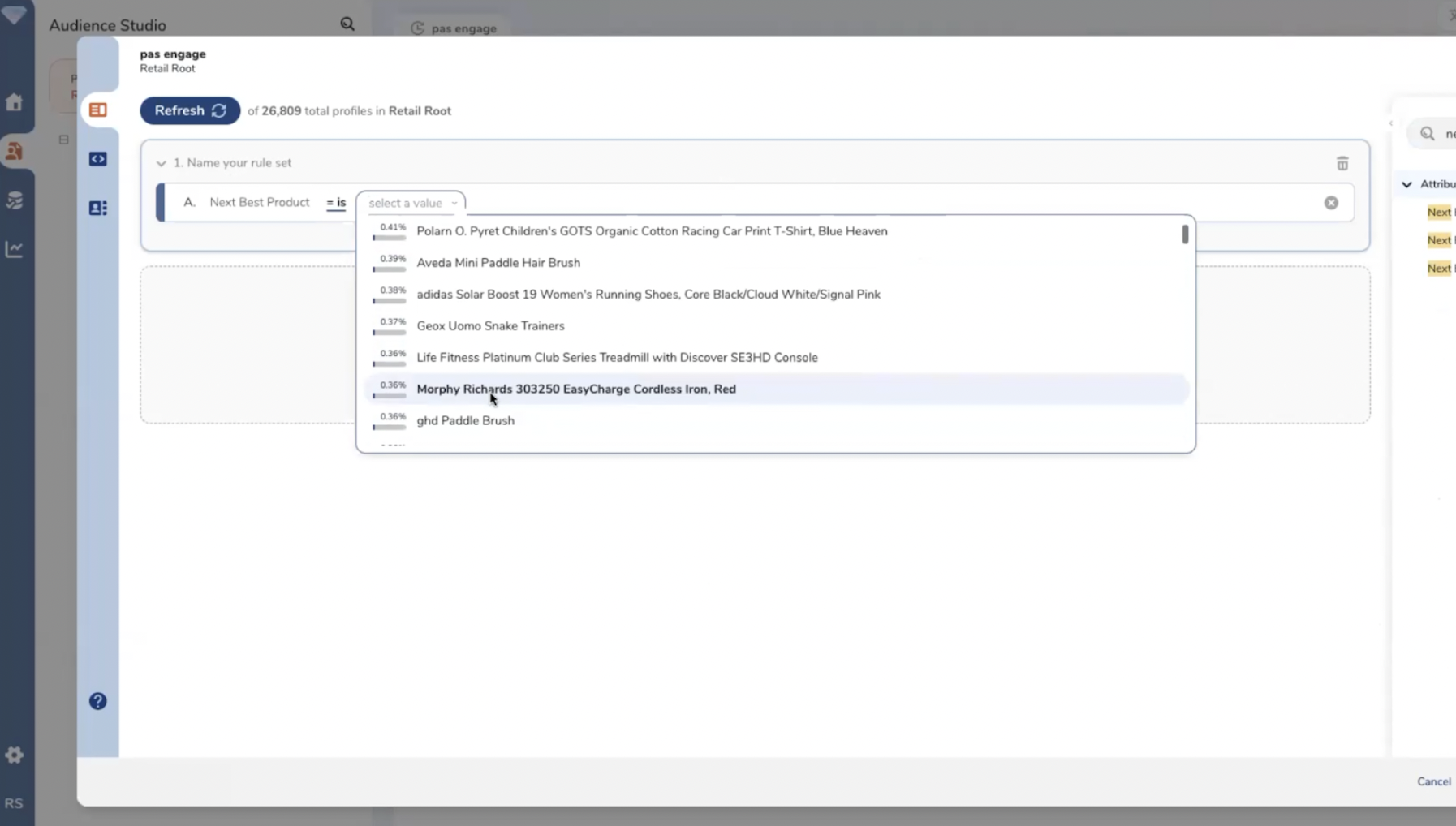
La définition des règles de segmentation (1).
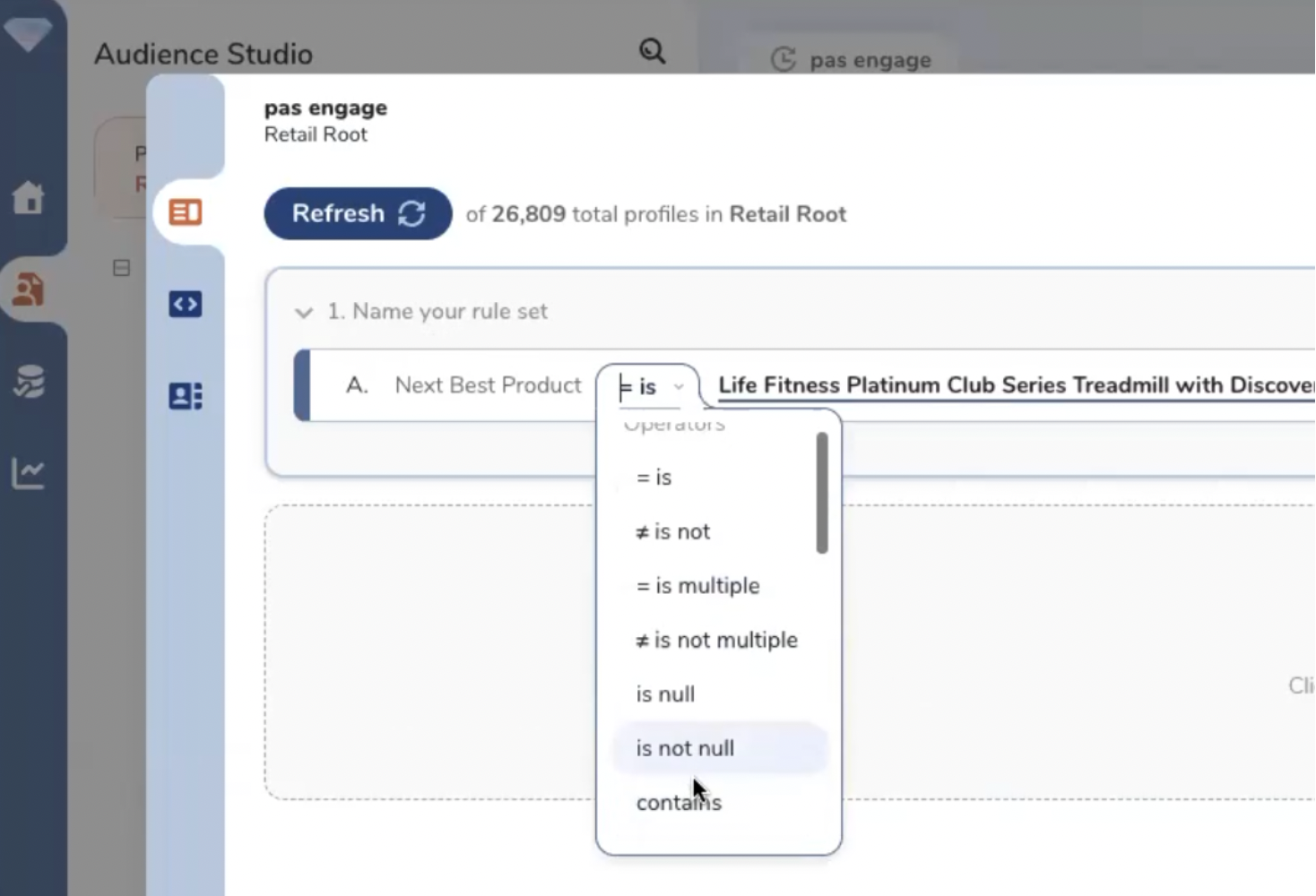
La définition des règles de segmentation (2).
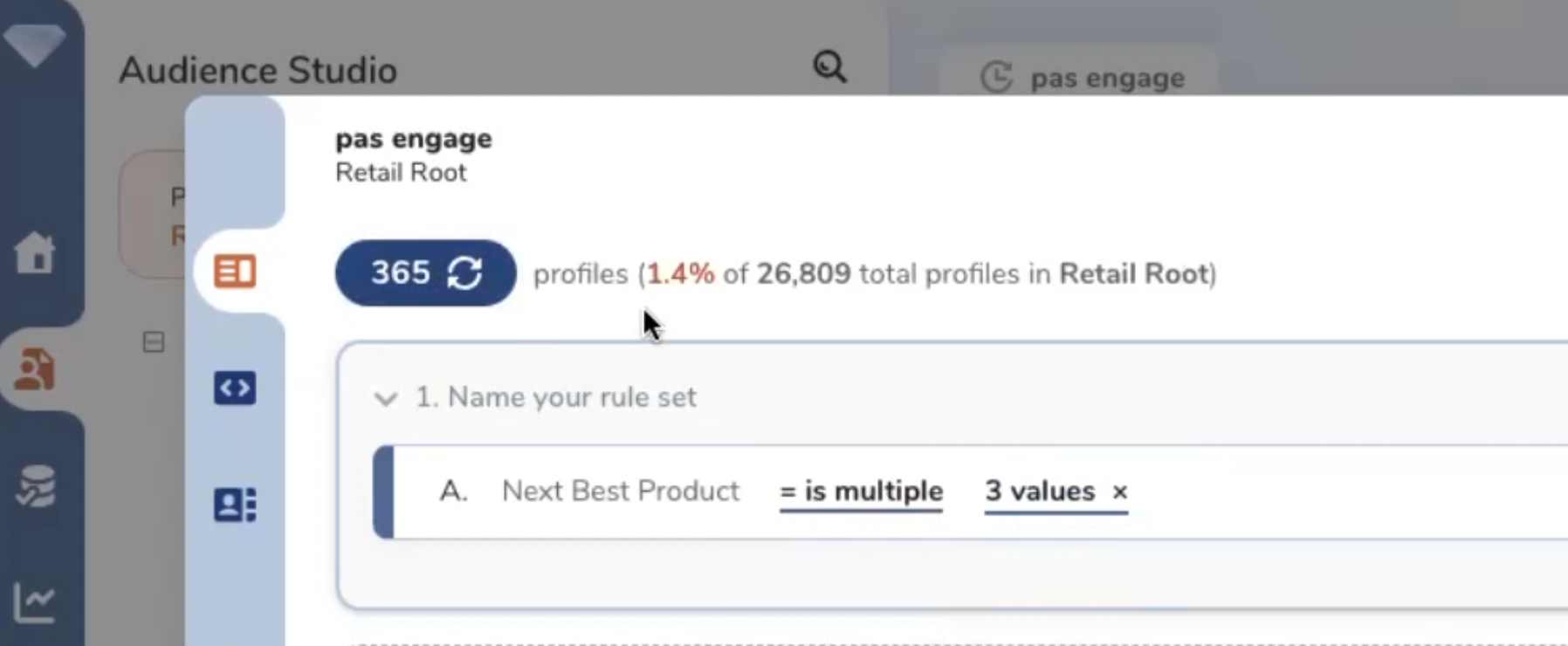
Un compteur temps réel permet de visualiser la population de chaque segment.
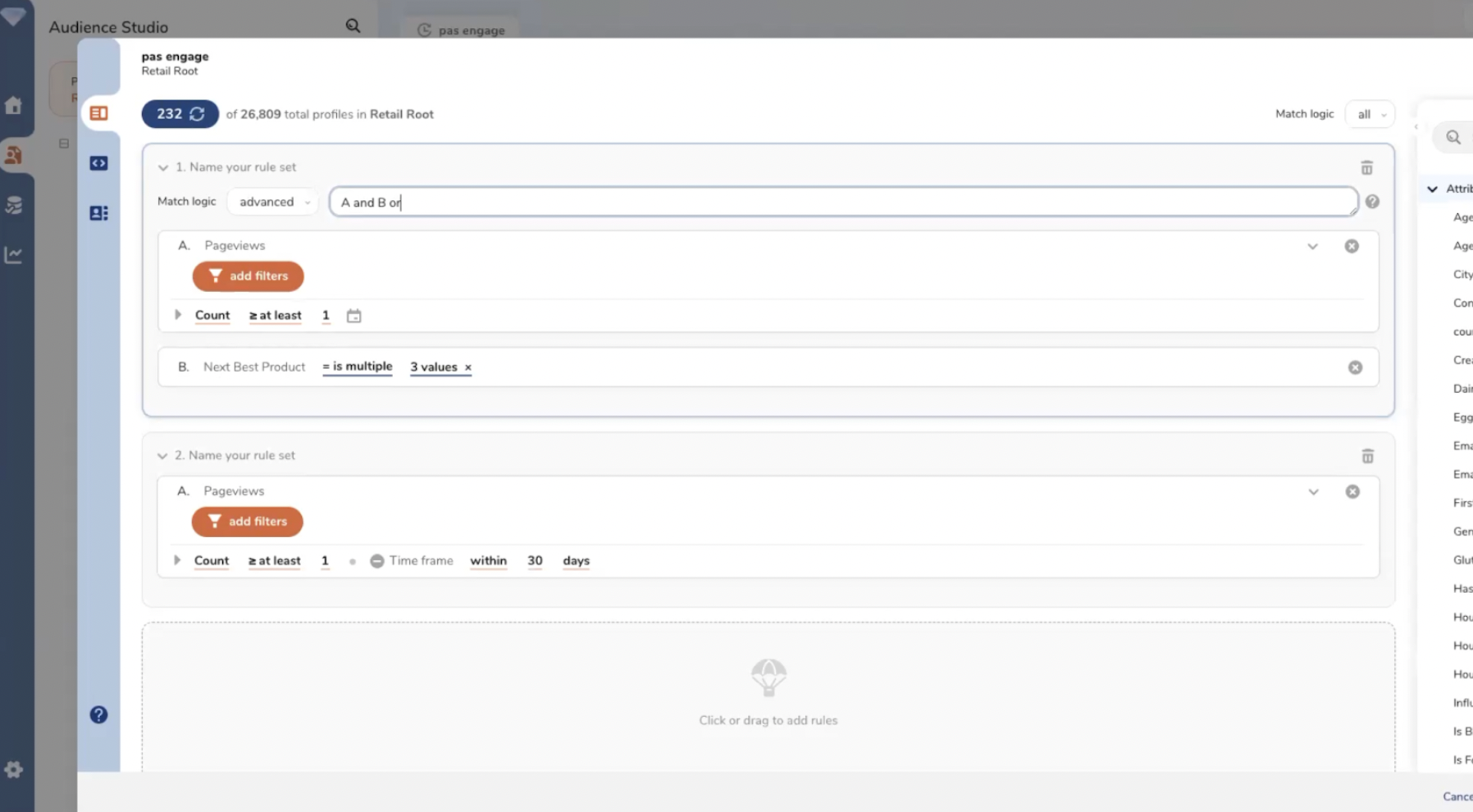
Treasure Data gère les opérateurs classiques (A and B or, etc.).
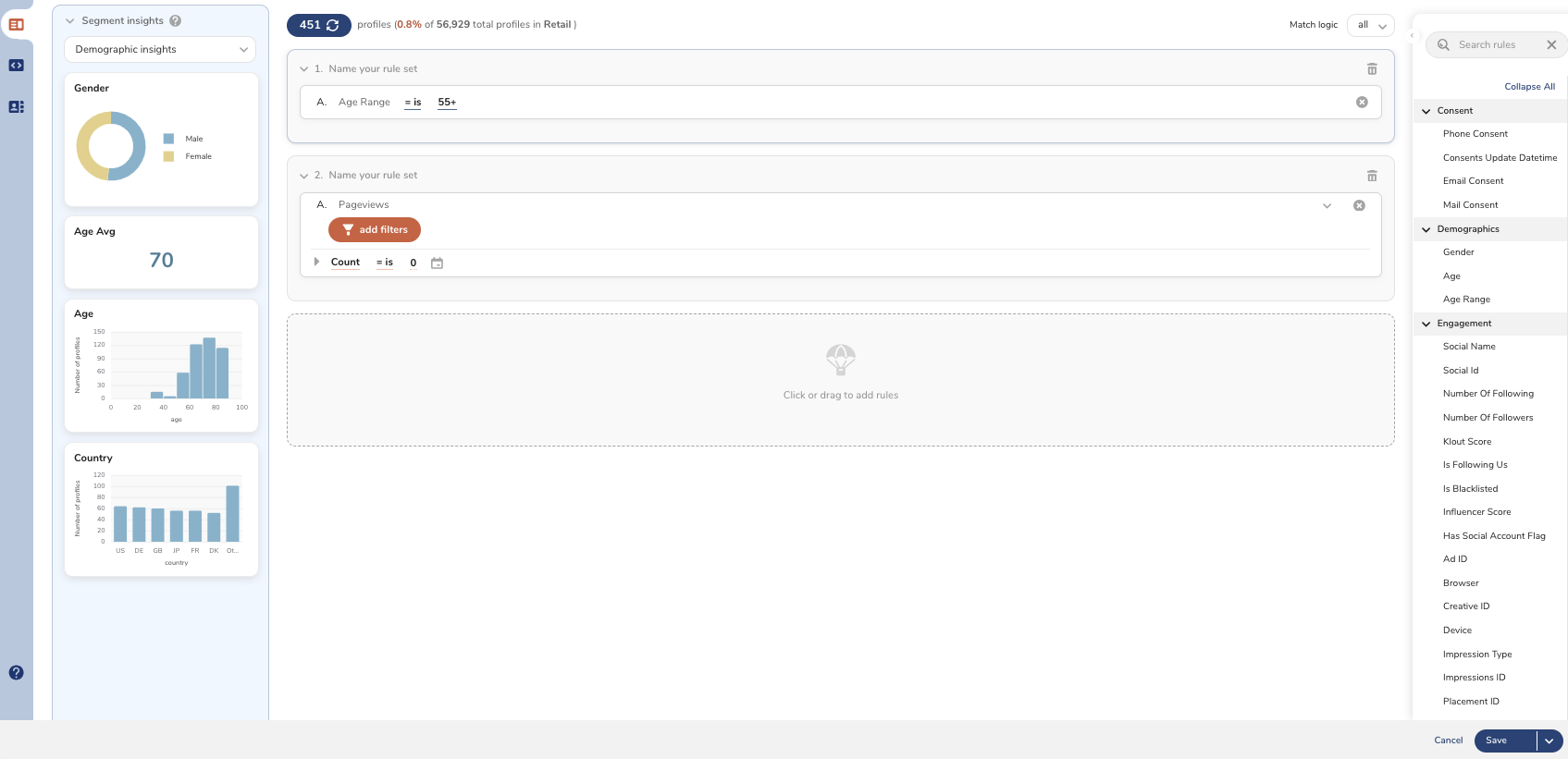
Treasure Data permet de connaître les informations clés relatives à chaque segment. La mise en page et le choix des insights présenté sont personnalisables.
Il est possible d’utiliser SQL en complément de l’éditeur no code.
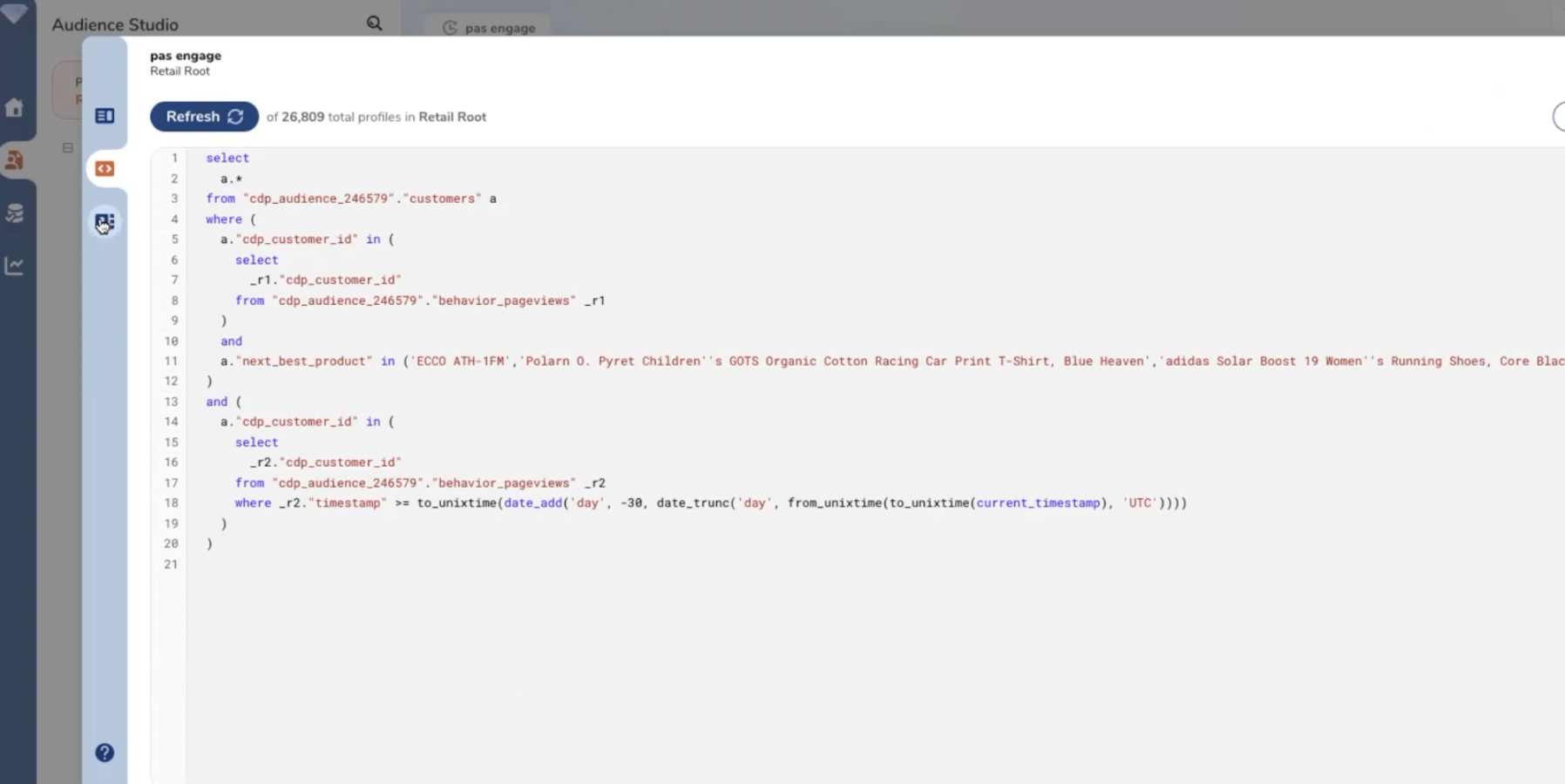
Légende : La segmentation en SQL.
Il est possible de visualiser la liste des profils qui matchent avec l’audience/segment cible, et d’accéder au détail de chaque profil.

Liste des profils intégrés dans l’audience.
Treasure Data propose de puissants algorithmes permettant de créer des scorings prédictifs. Par exemple, la probabilité de churn. Ensuite, ces scores peuvent être utilisés pour créer des audiences.
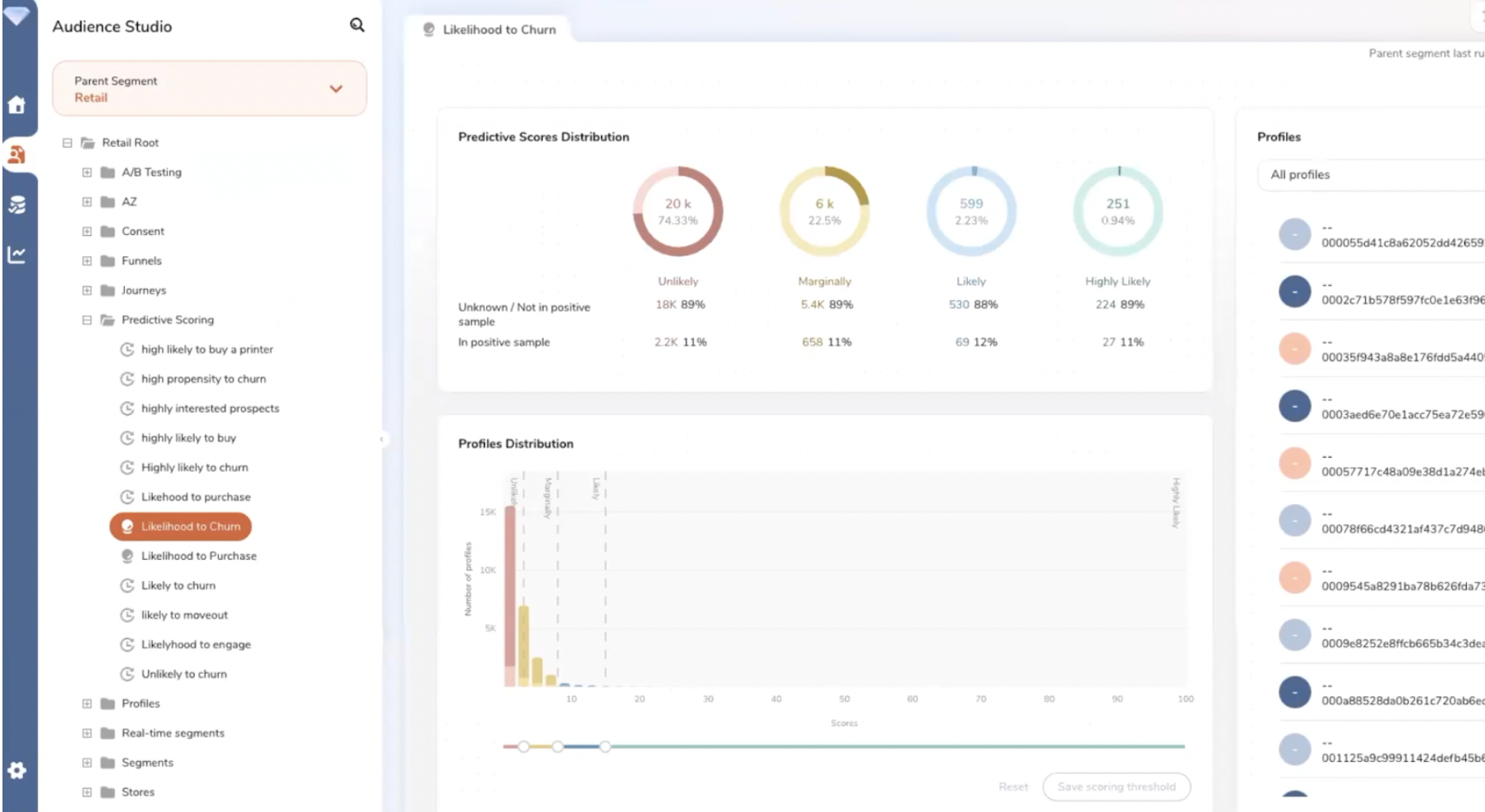
Treasure Data permet de calculer un score de probabilité de churn.
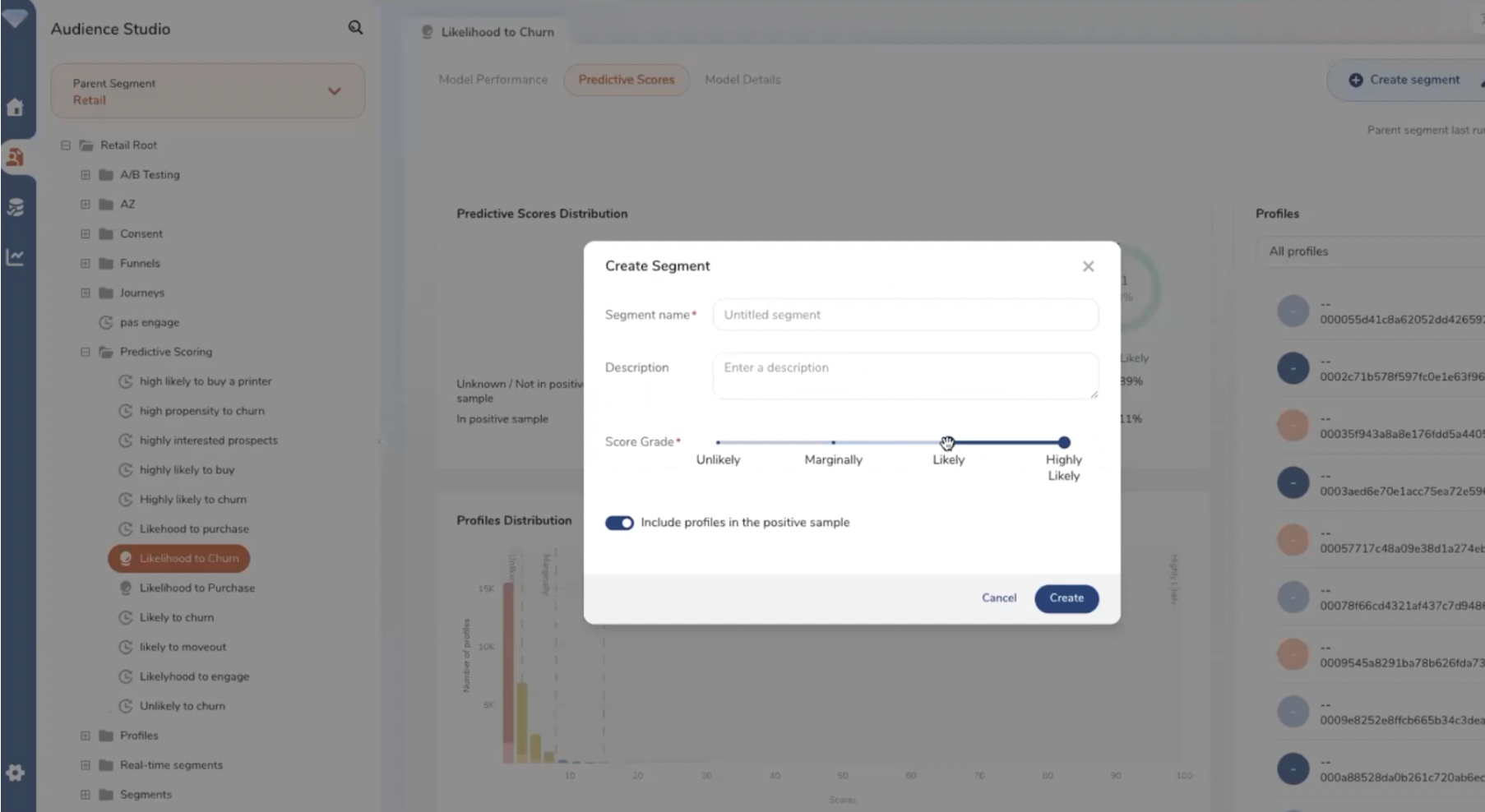
La création d’un segment sur la base d’un score prédictif (probabilité de churn).
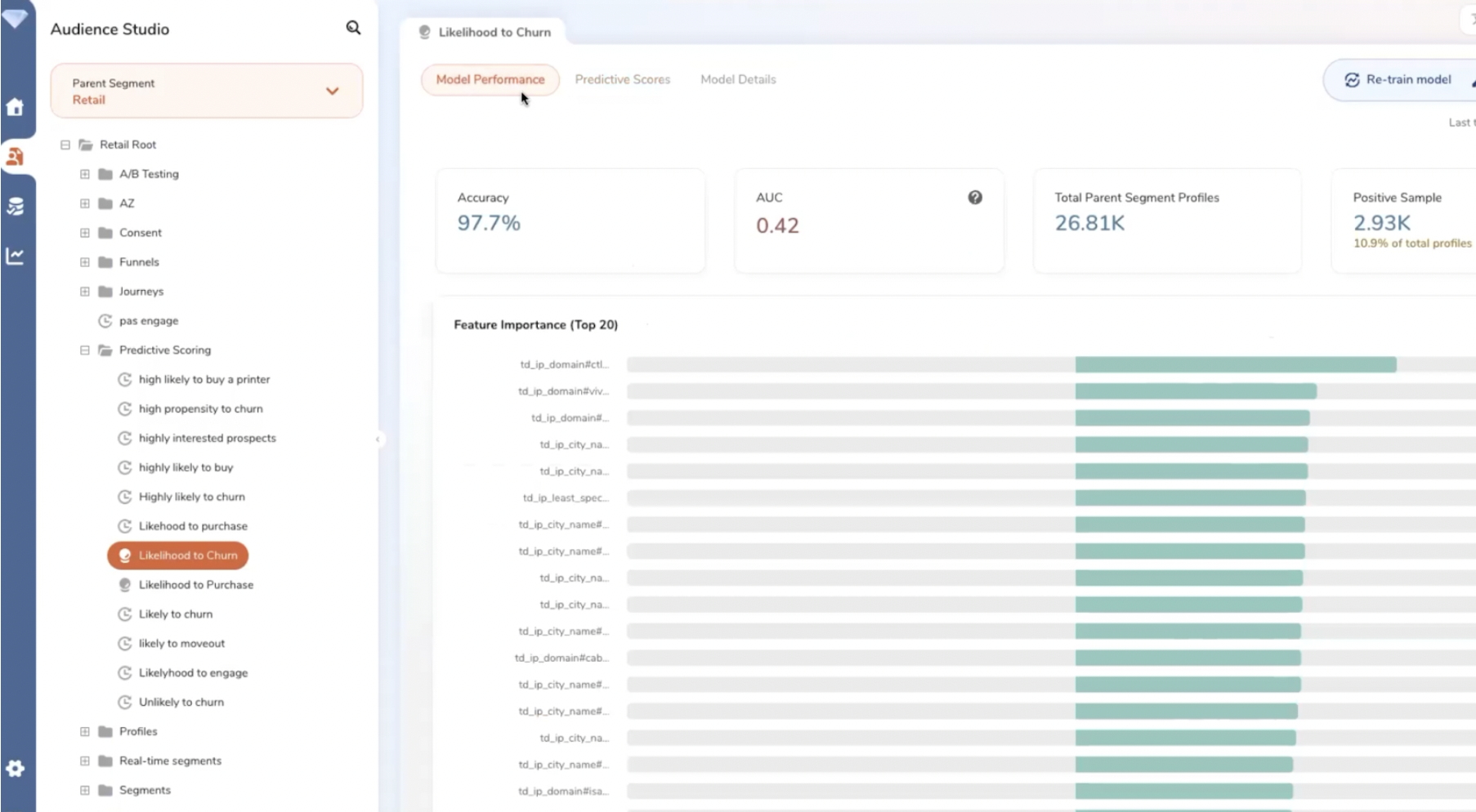
Détail du modèle prédictif utilisé pour calculer la probabilité de churn (1).
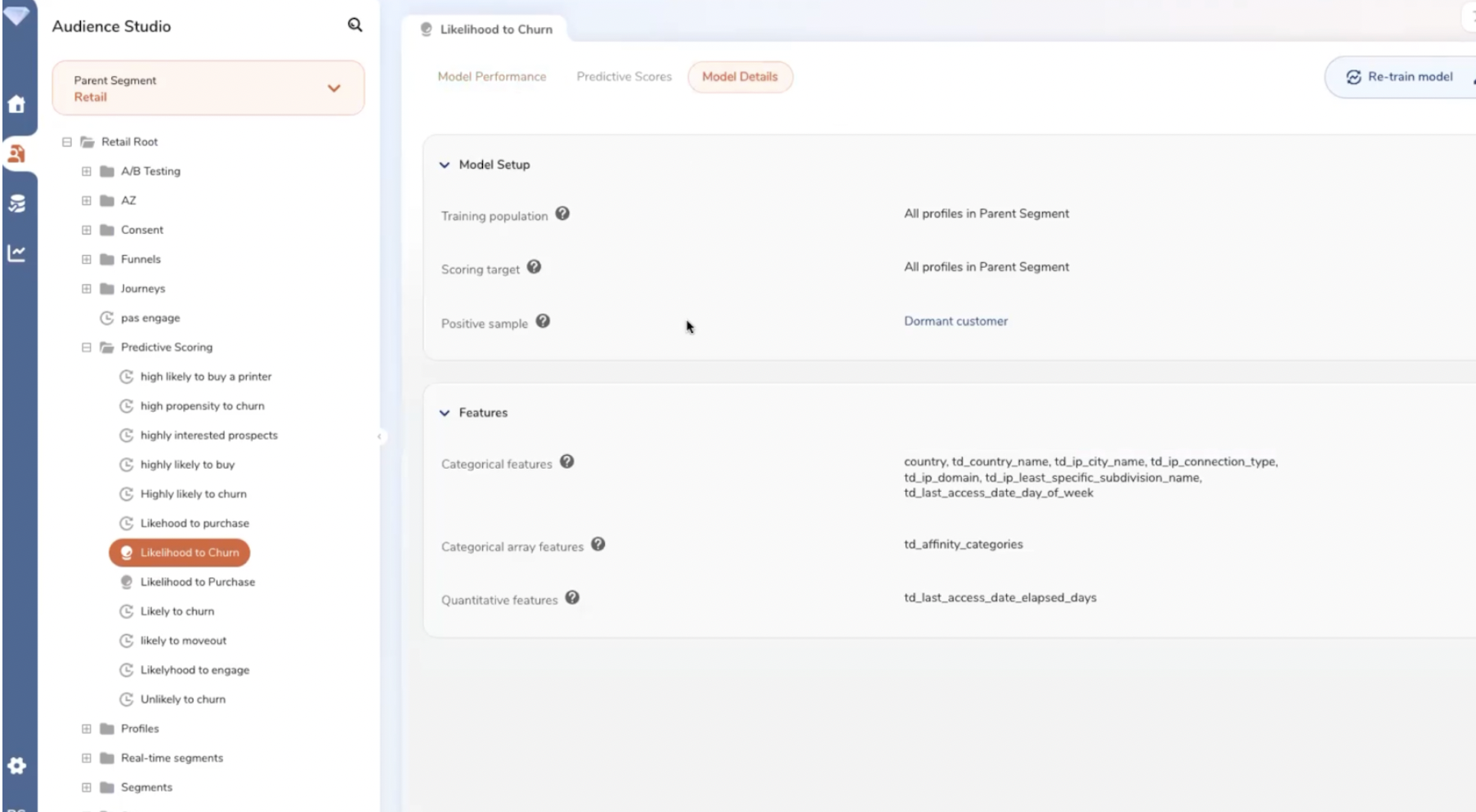
Détail du modèle prédictif utilisé pour calculer la probabilité de churn (2).
Treasure Data propose des modèles simples et no code de machine learning (avec 2 ou 3 attributs maximum) à destination des marketers et des modèles avancés à destination des data engineers/analysts. Il est par ailleurs possible d’intégrer des modèles prédictifs développés en dehors de la CDP (en Python ou en R).
Voici quelques-uns des modèles prédictifs sur l’étagère proposés nativement dans Treasure Data : Lifetime value, analyse de sentiment, canal préféré, heure de contact, prochaine action…
Orchestration & Activation
Treasure Data n’a pas vocation à remplacer les outils d’activation, mais à les orchestrer. La CDP Treasure Data permet d’unifier les données dans une vue 360, de les enrichir, de créer des scores et des audiences qui sont ensuite exportées dans les outils de Business Intelligence et d’activation.
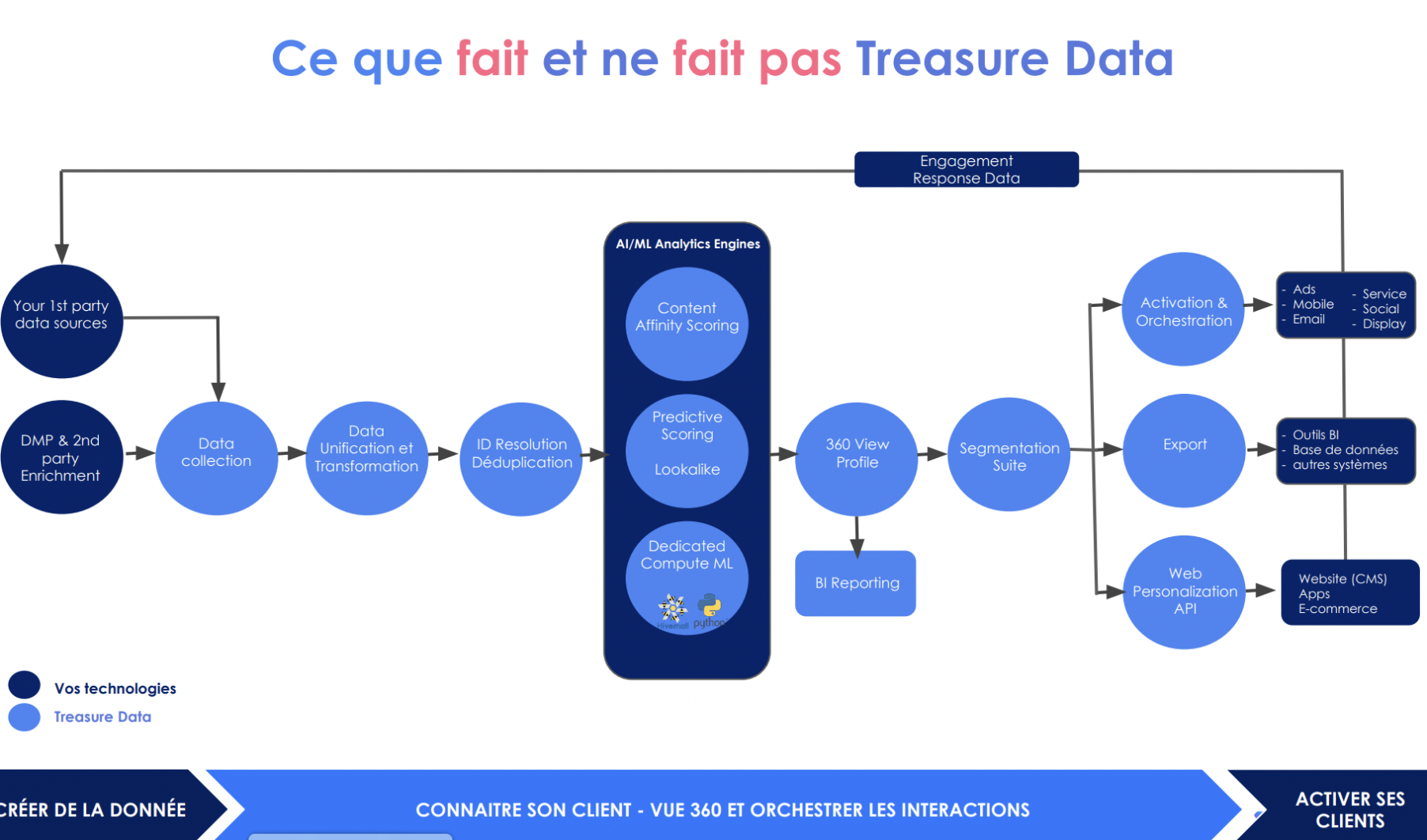
Treasure Data propose près de 200 connecteurs natifs avec des outils d’activation : CRM, marketing automation, ERPs, ecommerce, media, service client, BI, personnalisation web, A/B Testing. Tous les connecteurs sont développés et maintenus par Treasure Data.
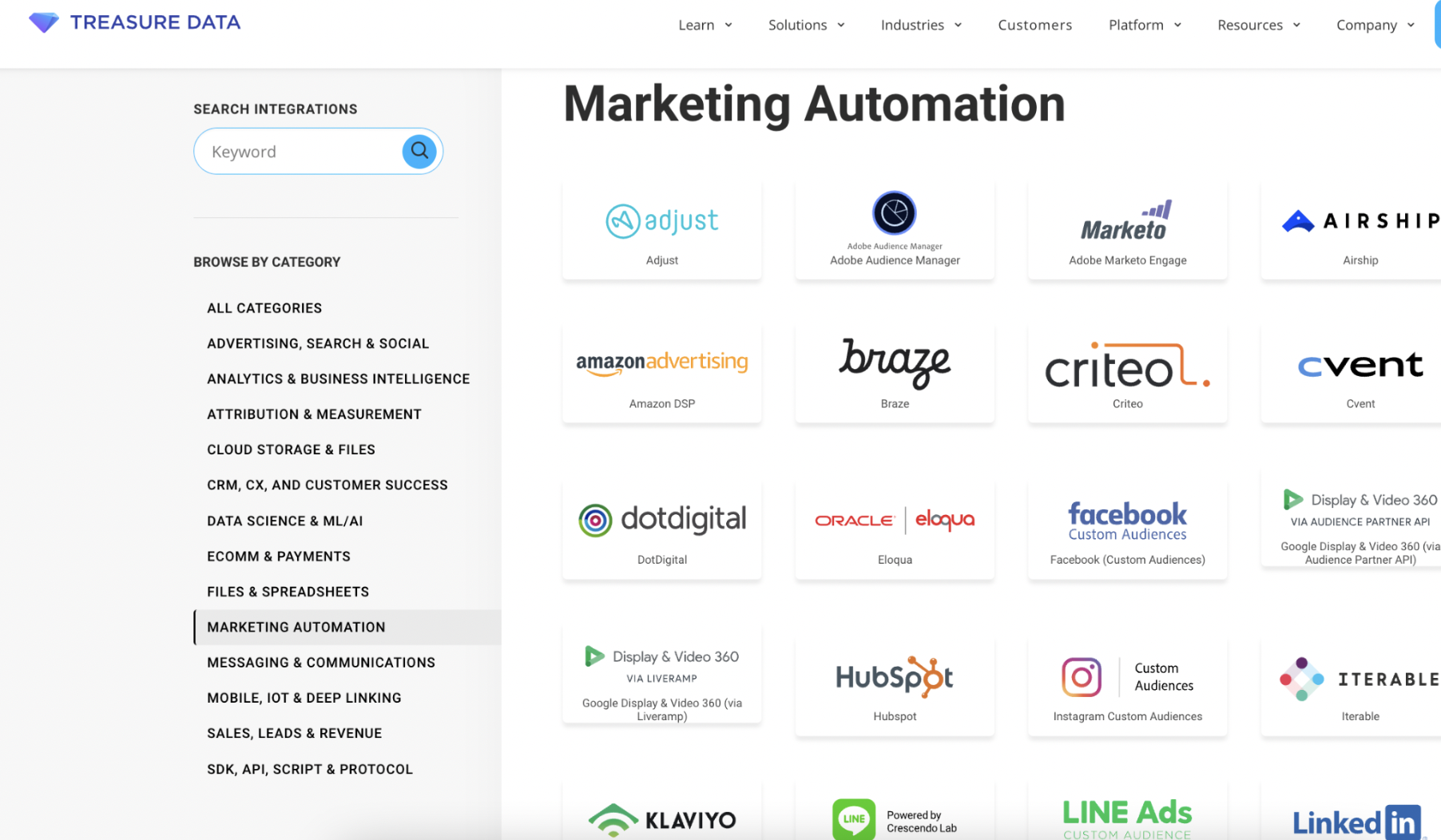
Liste des connecteurs proposés avec des outils de marketing automation.
Le paramétrage des flux d’export s’effectue depuis une interface no code utilisable par les profils métier.
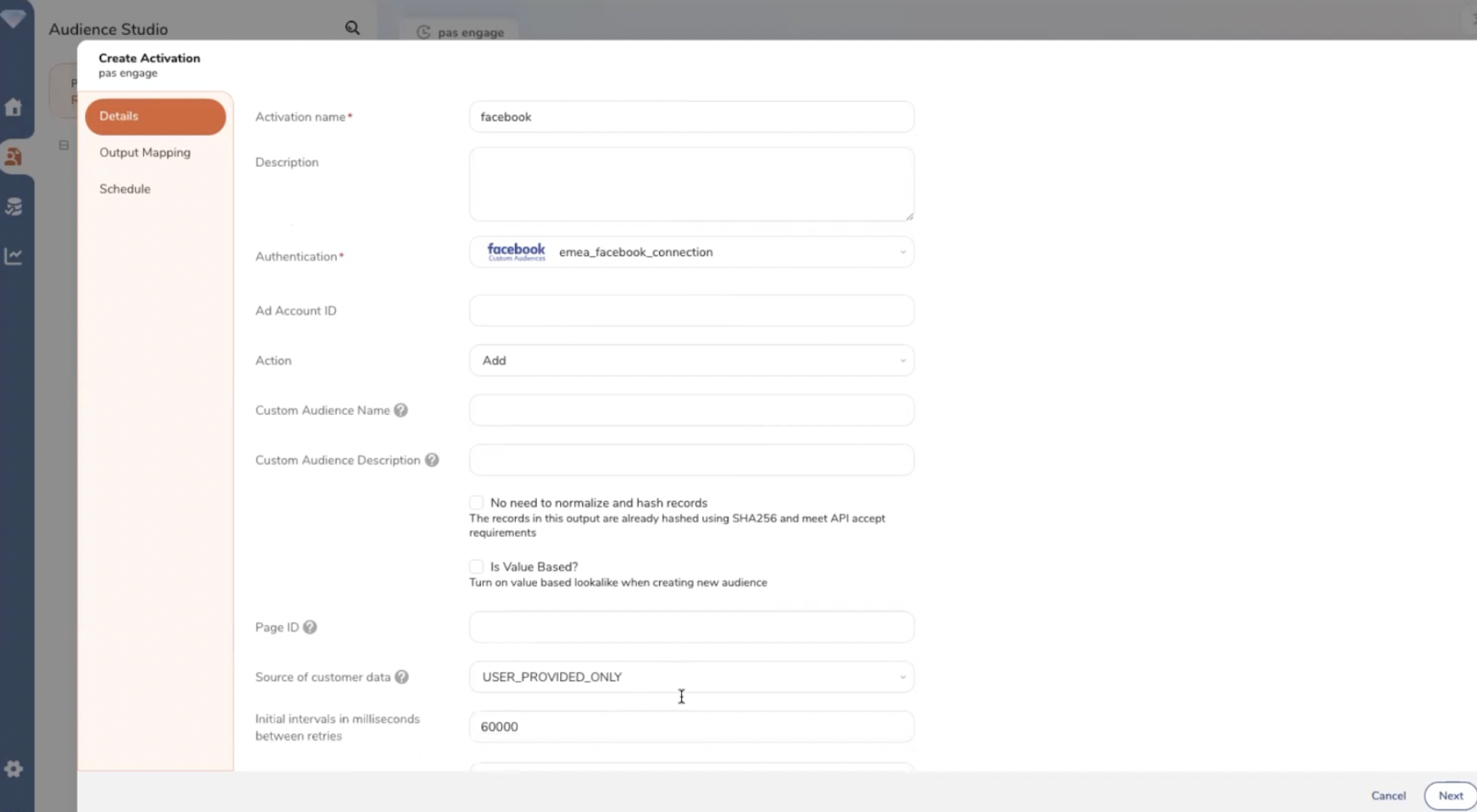
Paramétrage d’un flux entre la CDP et un outil de destination (1).
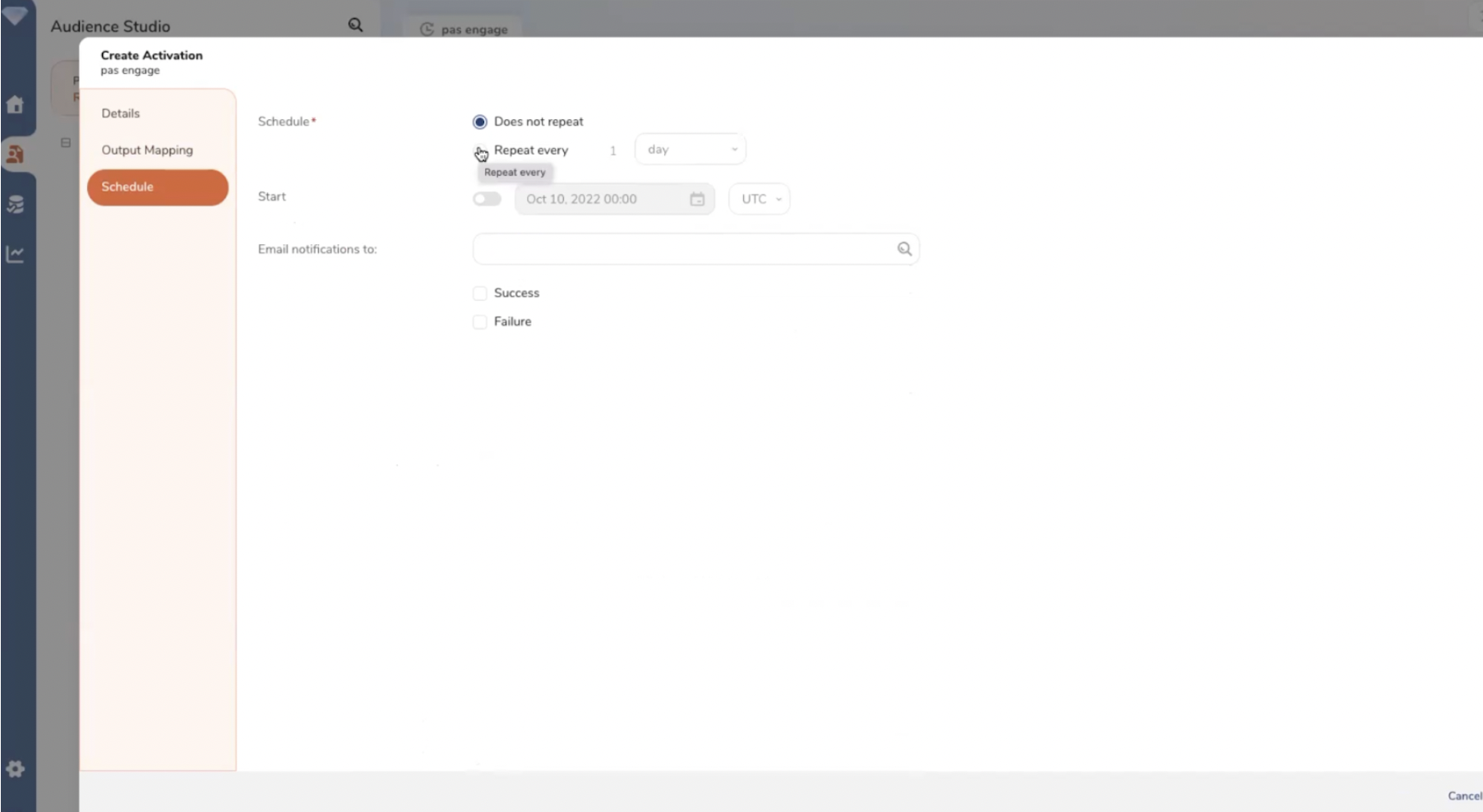
Paramétrage d’un flux entre la CDP et un outil de destination (2).
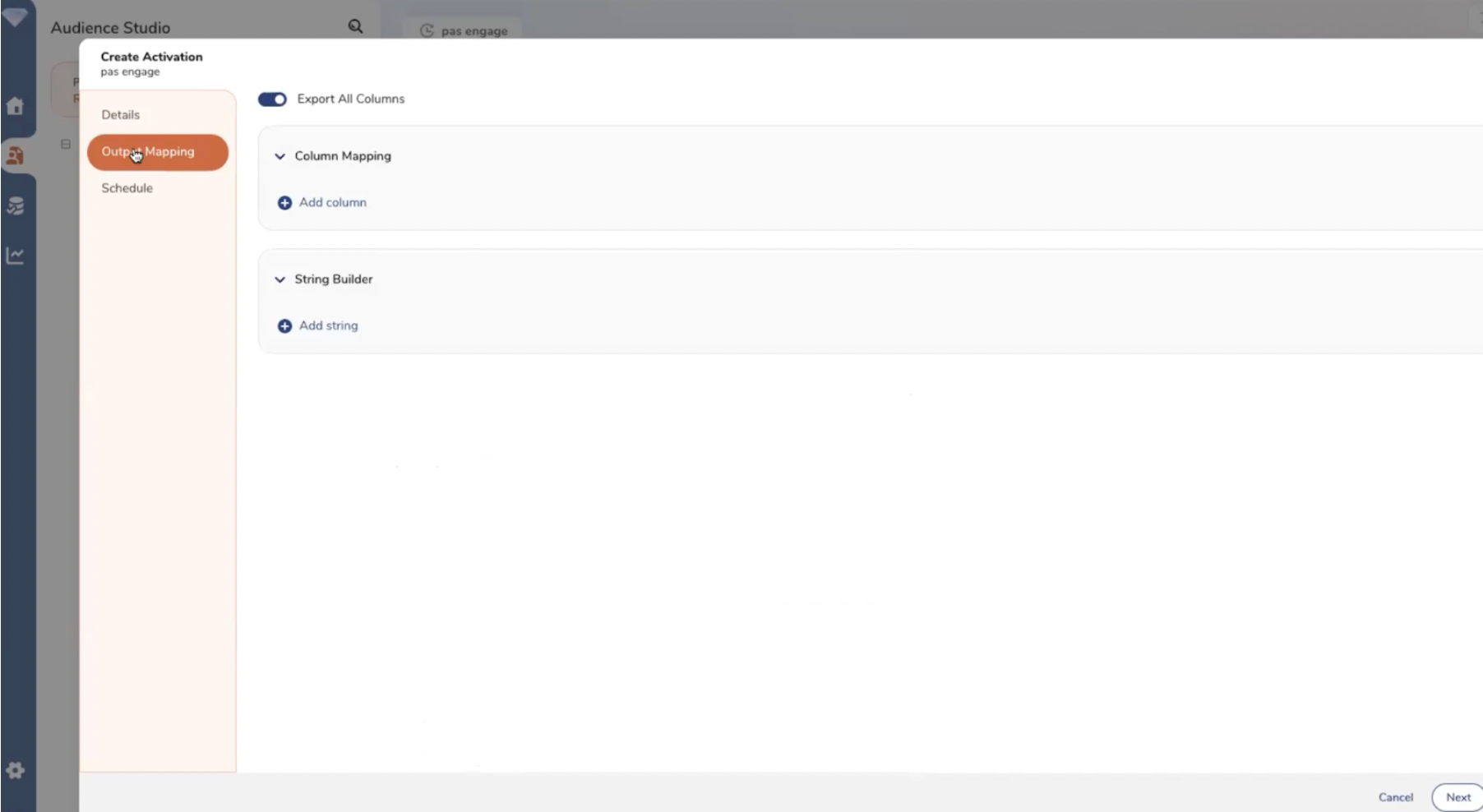
Paramétrage d’un flux entre la CDP et un outil de destination (3).
Treasure Data propose par ailleurs un module d’orchestration des parcours client fonctionnant comme une solution de marketing automation. Ce module est vendu en option. Il est régulièrement enrichi de nouvelles fonctionnalités (la dernière en date étant la possibilité de faire des A/B Tests).

Treasure Data commercialise un “Journey Builder”.
Stockage & Hébergement
La CDP Treasure Data est full SaaS, hébergée sur des serveurs cloud AWS. Treasure Data loue des serveurs aux USA, au Japon, en Corée du Sud et dans l’Union européenne (Francfort). Le client choisit sur quels serveurs il souhaite héberger ses données. Il n’y a aucune limite de stockage.
Projet
Les déploiements de Treasure Data peuvent être gérés directement par l’éditeur. Treasure Data travaille également avec des partenaires :
- Des cabinets de conseil pour structurer le projet en amont : cadrage des objectifs, des cas d’usage de la CDP, AMOA…
- Des intégrateurs pour le déploiement technique de la plateforme et la mise en place des premiers cas d’usage.
Treasure Data propose un programme partenaires dense comportant différents niveaux de certification : gold, silver…Seuls les partenaires certifiés peuvent intervenir sur les projets. La méthodologie de projet développé par Treasure Data est basée sur des approches agiles permettant d’accélérer la mise en place des premiers cas d’usage (environ 8 à 10 semaines).
La CDP Treasure Data est facturée en fonction du nombre de profils (connus et inconnus), du périmètre fonctionnel activé et du poids de l’infrastructure (stockage et computing).
Fiche éditeur Treasure Data
| Fiche éditeur Treasure Data | |
|---|---|
| Chiffre d'affaires - France | N/A. |
| Chiffre d'affaires - Monde | Revenus US 2022 : 136.1M$. |
| Nombre d'employés en France | 12 |
| Nombre d'employés dans le Monde | 674 |
| Nombre de clients en France | 9 |
| Nombre de clients dans le Monde | 450+ |
| Écosystème de partenaires en France (intégrateurs...) | Treasure Data travaille avec plusieurs partenaires basés en France : cabinets de conseil, intégrateurs, agences. |
| Support éditeur en France | Treasure Data propose un support en France et en français : équipe support (disponible 24/7 par email ou chat), customer success managers, technical account managers... |
| Possibilité de tester la solution ? | Treasure Data offre généralement une journée d'atelier sur site pour aider les potentiels clients à tester et qualifier la plateforme dans ses différentes dimensions. La démo est scénarisée en fonction des cas d'usage du client. |
CustUp est indépendant des éditeurs
Précision importante : CustUp est indépendant des éditeurs. Nous ne percevons aucune rémunération directe ou indirecte de leur part. Techno-agnostiques, nous recommandons à nos clients les solutions logicielles les plus en adéquation avec leurs ambitions et besoins.
CustUp vous accompagne dans votre Projet CDP
Cabinet de conseil en Performance Client et en Données Clients, nous aidons les entreprises dans le cadrage, le pilotage, le déploiement et l’exploitation de leurs Projets CDP. Nos accompagnements sont sur-mesure. Nous intervenons auprès d’organisations issues de tous secteurs (B2C et B2B) et de toutes tailles (de la PME au grand groupe).
Nous sommes en mesure de couvrir l’ensemble du périmètre d’un Projet Customer Data Platform :
- Cadrage des objectifs.
- Définition des besoins et des cas d’usage.
- Qualification des fonctionnalités cibles à opérer par la plateforme cible : unification – segmentation – activation – orchestration.
- Conception de l’organisation cible du SI Clients.
- Sélection de la Customer Data Platform : construction du dossier de qualification et copilotage de l’appel d’offres.
- Accompagnement à la maîtrise d’ouvrage en phase de déploiement.
- Accompagnement à l’amélioration de l’exploitation.
- Construction du dispositif de pilotage.
- Transformation des pratiques de marketing-ventes grâce à la Data et aux outils CRM.
- Propagation du projet CDP à l’international.
- …/…

Contactez notre expert

Clément Galopin
Diagnostique et met en place votre Relation Clients digitale
Vous avez des projets ? Parlons-en !
Indiquez-nous vos coordonnées et éventuellement quelques mots sur votre besoin, nous vous contacterons dans les plus brefs délais pour un échange.