Une brève introduction au Big Data – Définition, cas d’usages et glossaire
Quelle est la définition du Big Data ? Le « Big Data » est un terme générique employé pour désigner les stratégies et technologies mises en œuvre pour rassembler, organiser, processer et analyser de vastes ensembles de données. Le Big Data est l’art de gérer et d’exploiter de gros volumes de données.
Dans cette brève introduction au Big Data, nous allons vous présenter la définition du Big Data, ses principaux cas d’utilisation et ses concepts cardinaux.

Cabinet de conseil en Données Clients, CustUp accompagne les organisations dans l’optimisation de leur gestion des données pour une amélioration de la performance marketing et relationnelle.
Sommaire :
- Qu’est-ce que le Big Data ? [Définition simple]
- Qu’est-ce que le Big Data ? [Définition avancée & remise en contexte]
- Définition du Big Data par les 3 « V »
- Quelques cas d’usage du Big Data
- Intelligence Artificielle et Big Data : L’alliance incontournable
- Glossaire du Big Data – 25 définitions fondamentales
[Cet article a fait l’objet d’une mise à jour le 8 septembre 2023]
Qu’est-ce que le Big Data ? [Définition simple]
Le terme « Big Data » fait référence à des ensembles de données d’une taille et d’une complexité telles qu’ils défient les capacités des systèmes de gestion de données traditionnels.
Il ne s’agit pas simplement de la quantité, mais aussi de la variété (données structurées, non structurées, semi-structurées) et de la vélocité (la vitesse à laquelle les nouvelles données sont générées et collectées). Nous reviendrons plus loin dans l’article sur ces notions.
Disons-le d’emblée : il n’y a pas de définition unanimement partagée de la notion de « Big Data ». Cela ne signifie pas pour autant que Big Data est un terme fourre-tout ou vide. Au contraire, il renvoie à une réalité bien consistante. Dans notre métier de consultants en Données Clients, nous sommes régulièrement confrontés à des problématiques Big Data.
Big Data est utilisé pour désigner deux ensembles de choses :
- Les grosses bases de données.« Big Data » signifie d’abord« big volume of data ». Dans le Big Data, il y a l’idée qu’on ne gère pas de la même manière des bases de données classiques et des énormes volumes de données. A partir d’un certain seuil, la différence quantitative, volumétrique, se transforme en différence qualitative. Les process et traitements changent de nature. A partir d’un certain seuil, les données ne peuvent plus être gérées de manière classique, dans des bases et des outils classiques. Ce qui nous amène immédiatement au second point.
- Les dispositifs informatiques et plus largement les technologies utilisés pour gérer de gros volumes de données. Le Big Data ne renvoie pas qu’aux données en tant que telles, mais aussi aux technologies, aux stratégies, aux techniques utilisées pour gérer de gros volumes de données.
Les entreprises n’ont jamais eu autant de données à leur disposition, mais, pour la plupart, elles ne savent pas quoi en faire, elles n’en exploitent qu’une toute petite partie. Le Big Data, c’est avant tout l’art et la manière de faire un usage efficace de l’énorme volume de données que pratiquement toutes les organisations ont à leur disposition.
Le Big Data permet d’exploiter de manière optimale les données à disposition, d’en dégager le maximum d’enseignements (insights) à valeur stratégique, de trouver plus facilement les réponses aux questions que l’on se pose.
Faisons un rapide retour sur l’historique du Big Data. Il est intéressant à ce sujet de jeter un œil sur Google Trends. Avec cet outil, nous apprenons que l’on commence vraiment à « parler » de Big Data depuis…2012. Avant cette date, presque personne n’avait l’idée de taper « Big Data » dans Google.
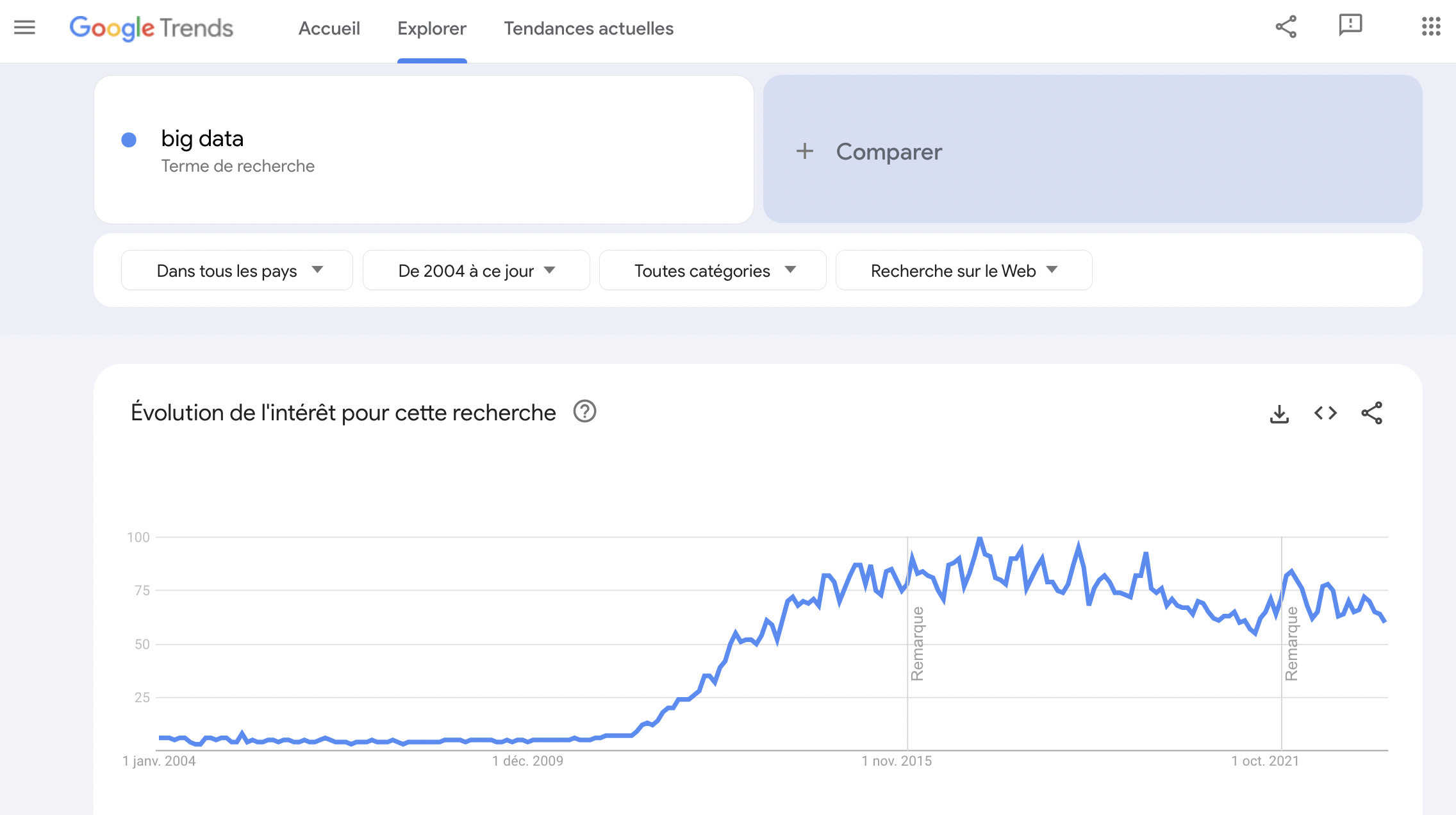
Ces statistiques Google Trends révèlent que le mot « Big Data » est relativement récent dans son usage. Mais il y a parfois une différence entre l’utilisation du mot et l’existence de la réalité. Les mots sont toujours créés après les réalités qu’ils désignent. Parfois la distance entre l’apparition du mot et la réalité de la chose est importante.
C’est le cas ici puisque les problématiques associées à la gestion de grands volumes de données remontent aux décennies 1960/70, autrement dit à la naissance de l’ « ère des données », à l’époque où les premiers data centers et les premières bases de données relationnelles sont apparus.
Mais c’est au milieu des années 2000 que les professionnels ont pris conscience du volume absolument vertigineux de données que brassaient des géants du net comme Facebook ou YouTube. C’est aussi dans les années 2000 que les volumes de données gérés par ces firmes et les grandes entreprises ont explosé, boostés par l’essor du digital.
Car c’est bien les données en provenance du digital qui ont entraîné cette explosion. C’est à cette époque qu’est apparu Hadoop, un framework open source écrit en Java et développé par Apache créé pour stocker et analyser de gros sets de données. C’est à cette même époque que les bases de données non relationnelles (NoSQL) ont gagné en popularité. Les bases non-relationnelles sont seules à même de gérer d’énormes volumes de données, contrairement aux bases de données relationnelles (SQL).
Signalons qu’Hadoop reste aujourd’hui encore la principale plateforme Big Data.
Apache Hadoop, la plateforme pionnière et leader pour les traitements Big Data.
L’émergence des frameworks open source, d’Hadoop à Spark (lui aussi développé par Apache), a joué un rôle essentiel dans le développement du Big Data. Ils ont permis de faciliter la gestion de données massives et de réduire considérablement ses coûts de stockage.
Depuis cette époque, le volume de données a grimpé en flèche. Le Big Data du milieu des années 2000 n’est plus le Big Data de 2021. Le développement de l’internet des objets contribue a accentué cette tendance à l’explosion volumétrique des données.
Avec l’internet des objets, de plus en plus d’objets et d’appareils du quotidien sont connectés à internet, ce qui permet aux entreprises qui les commercialisent de collecter en continu des données sur le comportement et l’usage des consommateurs vis-à-vis de ces objets et appareils.
Si les problématiques associées au Big Data sont anciennes, ce n’est vraiment que maintenant qu’elles sont devenues impérieuses. Le Big Data devient indispensable pour les grandes entreprises.
Pour mieux comprendre ce qu’est le Big Data et les problématiques qu’il soulève, apportons quelques précisions quant à sa définition. Dans le Big Data, la question du « volume » n’est pas le seul défi.
Les prérequis fondamentaux pour travailler avec des Big Data sont les mêmes que ceux nécessaires pour travailler avec des bases de données classiques. Dans les deux cas, il s’agit de gérer des données : stockage, transformations et traitements divers et variés, BI, activation…Avec le Big Data, nous restons dans le monde plus large du Data Management.
Néanmoins, l’échelle massive des données à traiter, la vitesse d’ingestion et de processing, les caractéristiques des données qui doivent être processées à chaque étape de traitement font émerger de nouveaux challenges technologiques.
L’objectif principal du Big Data est de réussir à faire apparaître des enseignements (insights) et des connexions entre de gros volumes de données de nature hétérogène qui seraient impossible à obtenir avec les méthodes classiques d’analyse des données.
En 2001, Doug Laney, un analyste de chez Gartner, a donné une définition intéressante du Big Data. Pour expliquer ce qu’est le Big Data, il a présenté la théorie des 3 V. C’est un mode de présentation du Big Data simple et efficace. Elle permet de mieux appréhender la définition du Big Data. Selon Doug Laney, le Big Data peut se comprendre à partir de trois notions ayant tous la particularité de commencer par la lettre « V » :
- Volume. Un système Big Data se caractérise d’abord par le volume de données en jeu. Un système Big Data traite un volume de données largement supérieur à ce que traitent les bases de données traditionnelles. Ce qui pose un défi technologique : les volumes de données en jeu excèdent les capacités de stockage d’un simple ordinateur, nécessitent des mises en réseau, l’utilisation du Cloud Computing…L’infrastructure IT sous-jacente doit être en mesure d’accueillir, de digérer et de traiter ces gros volumes de data.
- Vélocité. Depuis le début, nous insistons sur la problématique du volume. Dans Big Data, il y a évidemment « Big ». Mais dans le Big Data, le volume n’est pas le seul sujet. Un système Big Data, c’est aussi un système dans lequel la donnée circule vite entre les outils, les bases, les applicatifs, les sources. Les données arrivent dans le système en provenance de sources multiples et sont processées souvent en temps réel pour générer des insights et mettre à jour le système. Dans le Big Data, l’approche orientée « batch » tend progressivement à céder sa place au streaming de données en temps réel ou quasi-temps réel. Dans certains cas d’usage du Big Data, le temps réel ou le quasi temps-réel sont nécessaires.
- Variété. Les données sont en grand nombre et circulent vite dans le système. Mais ce n’est pas tout. Le Big Data se caractérise aussi par l’immense variété des données traitées. Les bases de données relationnelles ont affaire à des données structurées, bien définies, bien classées, bien normées. Un Data Warehouse organise de manière structurée des données structurées. Dans le Big Data, les données sont dans leur majorité non-structurées ou semi-structurées. C’est pour cette raison que Big Data rime davantage avec Data Lake qu’avec Data Warehouse.
En résumé, le Big Data est l’art de gérer de gros volumes de données, complexes et hétérogènes, pour la plupart non structurées, qui doivent circuler vite dans un système donné. Ce n’est pas possible avec les technologies classiques de gestion de données. C’est pour cette raison qu’une définition du Big Data ne doit pas simplement se concentrer sur les données, leur volume, leur format, mais aussi sur les technologies qui rendent possible les traitements Big Data.
Certains auteurs ou éditeurs de logiciels ont voulu ajouter d’autres « V » aux trois proposés par Gartner, pour mettre en avant d’autres défis posés par le Big Data :
- Véracité. La variété des sources et la complexité des traitements peuvent poser des problèmes en ce qui concerne l’évaluation de la qualité des données (et, in fine, la qualité des analyses faites à partir d’elles). La problématique de la Data Quality est structurante dans n’importe quel projet Big Data.
- Variabilité. La variabilité des données entraîne une variation de leur qualité. Le fait que les données évoluent dans le temps peut entraîner une dégradation de leur qualité. Dans un système Big Data, il est important d’avoir à disposition des outils permettant d’identifier, de traiter et de filtrer les données de faible qualité pour en optimiser l’utilisabilité.
- Valeur. Le défi ultime du Big Data est de créer de la valeur. Or, parfois, les systèmes et les procédures en place sont si complexes qu’il devient difficile d’extraire de la valeur des données à disposition (d’en dégager des insights). La valeur rappelle la finalité business de tout projet Big Data – cette finalité business peut être atteinte directement (programmes & scénarios relationnels basés sur le Big Data) ou indirectement (via les analyses de BI).
La recommandation de produits
Une entreprise comme Netflix utilise le Big Data pour anticiper la demande de ses clients. Les équipes de Netflix ont construit des modèles prédictifs afin de proposer aux clients des nouveaux produits et services basés sur les attributs des produits et services consommés par le passé. Netflix utilise le Big Data pour créer des modèles de recommandation très élaborés, que vous connaissez certainement.
Les suggestions Netflix : un cas d’utilisation du Big Data.
L'anticipation de la maintenance
Les facteurs qui permettent de prédire les problèmes mécaniques sont souvent dissimulés dans des ensembles de données structurées : l’année d’équipement, l’année de fabrication, le modèle du produit ou bien dans des données non-structurées : messages d’erreur, connexions, données de capteur, température…
Analyser toutes ces données, qui constituent autant d’indicateurs, permet d’anticiper les pannes et la survenue de problèmes.
Le Big Data peut être utilisé pour réduire le coût de la maintenance et allonger la durée de vie en bon état des produits.
L'amélioration de l’expérience client
L’expérience client est la résultante des sentiments et émotions ressentis par le client dans sa relation avec une marque, au sens large. Elle s’évalue et mesure par l’analyse de toutes les interactions entre le client et la marque.
Le Big Data permet de collecter les données en provenance de tous les canaux, de tous les points de contact (réseaux sociaux, visites web, appels, etc.) et de qualifier de manière relativement précise l’expérience vécue par chaque client. La qualité de cette mesure permet d’améliorer la pertinence/ personnalisation des offres, de réduire le churn et de résoudre les problèmes de manière pro-active.
La création de modèles de Machine Learning
Le machine learning est une approche basée sur le Big Data. Les deux sont irrésistiblement liés. La donnée massive est la matière première du machine learning. Le machine learning mériterait un article à lui tout seul. Il consiste à instaurer un nouveau rapport à la machine, à passer d’un rapport de programmation (l’homme programme une machine) à un rapport d’enseignement, de learning.
Le machine learning est l’art de rendre la machine apprenante, donc intelligente (dans une certaine acceptation du terme…). Le machine learning (et plus généralement l’IA) est indubitablement une des applications les plus prometteuses du Big Data.
L'amélioration de l’efficacité opérationnelle
L’efficacité opérationnelle – c’est-à-dire l’efficacité des process & traitements déployés par les hommes et les machines – fait moins parler d’elle que le machine learning, pourtant c’est l’un des domaines où le Big Data a / aura le plus d’impact. Le Big Data permet d’analyser et d’évaluer tout type de production humaine et les feedbacks clients. Le Big Data peut être utilisé pour améliorer la prise de décision, pour l’ajuster au mieux à la demande du marché.
Nous ne prétendons pas avoir résumé toutes les utilisations du Big Data. Elles sont nombreuses et croissantes. Mais ces quelques cas d’usage permettent déjà de percevoir toute la valeur d’une utilisation intelligence des données massives.
Signalons quelques autres cas d’utilisation du Big Data dont nous aurions pu parler :
- La vue client unique qui permet aux collaborateurs de l’entreprise d’avoir accès sur une interface simple à l’ensemble des données disponibles sur n’importe quel client. Le Big Data est aussi l’art et la manière d’unifier la donnée clients, en construisant des infrastructures adéquates de type Référentiel Client Unique.
- La prévention des fraudes. Sujet moins glamour, mais important dans certains secteurs, en particulier le secteur bancaire. Une carte bancaire est utilisée pour réserver une voiture à Singapour alors que son détenteur vit à Paris, est localisé à Paris et n’est pas en période de congés ? Le rapprochement de ce genre de données et d’événements permet de détecter des fraudes possibles et de déclencher des actions pro-actives.
- L’optimisation des prix. Vous connaissez toutes et tous le yielding, qui consiste à ajuster en temps réel les prix en fonction de l’analyse de l’offre et de la demande. Les sociétés de transport (notamment aériens) utilisent cette technique de manière massive. C’est un cas d’utilisation du Big Data parfois peu apprécié des consommateurs finaux, mais qui doit être mentionné.
- L’analyse en temps réel des interactions sur les réseaux sociaux. Difficile de contrôler tout ce qui se dit sur les réseaux sociaux de la marque lorsque les messages, commentaires, likes et autres posts se comptent par centaines de milliers. Le traitement 100% humain devient impossible. Les grands groupes développent des algorithmes basés sur le Big Data pour mieux contrôler leur présence sur les réseaux sociaux et tirer des enseignements de la Voix du Client.
- Les objets connectés génèrent des volumes de données énormes. Pour les stocker, les analyser, les exploiter, les technologies et pratiques Big Data sont incontournables.
L’intelligence artificielle est au centre des attentions depuis fin 2022 et la sortie de ChatGPT. L’IA est devenue un sujet grand-public. La courbe de Google Trends est à cet égard significative.
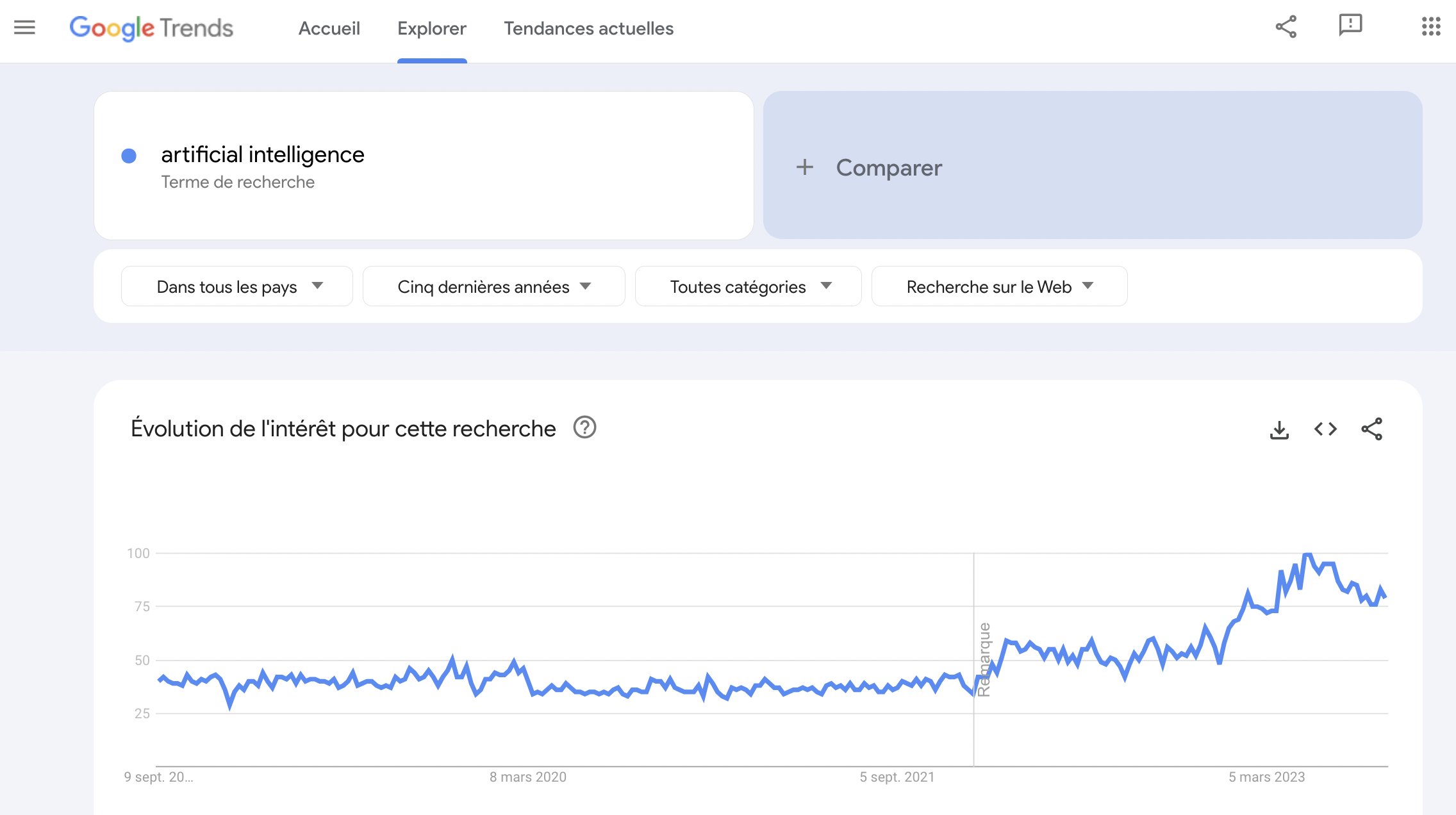
Les interactions entre IA et Big Data sont intimes. Prenons une métaphore : si l’on considère l’Intelligence Artificielle (IA) comme un artiste, alors le Big Data est sa toile et ses pinceaux. Il ne s’agit pas d’une simple métaphore, mais d’une réalité technologique.
L’IA, dans ses applications les plus modernes et performantes, repose sur des méthodes d’apprentissage automatique, ou machine learning. Pour « apprendre », ces algorithmes nécessitent des données, beaucoup de données. Imaginez essayer d’apprendre une nouvelle langue en ne lisant qu’une seule page d’un livre. Vous n’iriez pas loin…De même, une IA qui ne dispose que d’un ensemble limité de données aura du mal à déduire, prévoir ou comprendre des patterns complexes. C’est ici que le Big Data intervient.
Le Big Data fournit le carburant nécessaire aux moteurs d’IA. Pour un modèle de langage, par exemple, cela signifie analyser des milliards de phrases pour comprendre la structure, le sens et le contexte. Pour une IA analysant des images, cela signifie passer au crible des millions de photos pour identifier un objet, un visage ou un geste.
En retour, l’IA offre les outils nécessaires pour trier, analyser et extraire des informations pertinentes de ces énormes volumes de données. Sans IA, il serait presque impossible d’extraire des connaissances utiles de ces océans d’informations.
En conclusion, pas d’IA sans Big Data, et le Big Data sans IA serait comme une bibliothèque sans bibliothécaire. Ces deux technologies, en symbiose, redéfinissent les frontières du possible dans des domaines aussi variés que la médecine, la finance, l’art et bien d’autres. L’avenir est prometteur pour cette alliance, à condition, bien sûr, d’aborder avec prudence et éthique les questions liées à la vie privée et à l’utilisation des données.
Glossaire du Big Data - 25 définitions fondamentales
Terminons ce bref exposé du Big Data par un glossaire. Pourquoi ? Pour comprendre un sujet, il est important d’en connaître les concepts et les mots. Dans le cadre d’un article d’introduction au Big Data, il nous a semblé utile de proposer une définition des principales notions liées de près ou de loin au Big Data.
Algorithmes
On ne peut pas parler de Big Data sans parler d’algorithmes. Pour donner une définition synthétique, un algorithme est une formule mathématique ou un ensemble d’instructions données à une machine qui décrit comment la donnée doit être processée pour obtenir l’information voulue.
Batch Processing
Le batch processing est une réalité ancienne. Il consiste à séquencer le traitement des données, à traiter les données par lots. Le Big Data a donné une nouvelle jeunesse à ce concept. Le framework Hadoop est basé sur cette méthode de traitement. Le batch processing s’oppose au streaming de données en temps réel.
Big Data
Big Data est un terme générique qui désigne les datasets qui ne peuvent pas être gérés par des serveurs et des outils classiques en raison de leur volume, de leur vélocité et de leur variété. Le concept de Big Data fait aussi référence aux technologies et aux stratégies mises en œuvre pour gérer ce type de données.
Business Intelligence
La Business Intelligence (souvent désignée par son acronyme BI) est la démarche qui consiste à analyser de gros volumes de données pour en extraire des enseignements (insights), c’est-à-dire des informations à valeur ajoutée permettant d’améliorer et de mieux comprendre son activité. La BI est utilisé pour améliorer la prise de décision (data-driven).
Cloud Computing
Le Cloud Computing désigne le fait d’utiliser internet (ie. des serveurs distants) pour stocker les données et organiser leur accès, en lieu et place d’un disque dur d’ordinateur. Le cloud computing, en démultipliant les possibilités de stockage et en facilitant l’accès aux données, a joué et continue de jouer un grand rôle dans l’essor du Big Data.
Cluster Computing
Un seul ordinateur ne peut pas traiter les volumes de données qui sont ceux du Big Data. Le cluster computing consiste à mettre en réseau plusieurs ordinateurs / serveurs pour créer des systèmes ayant la capacité de réaliser des traitements Big Data.
Data Engineer
Spécialiste en informatique responsable de la conception, de la construction et de la maintenance des architectures de données, comme les bases de données et les grands systèmes de traitement de données. Leur rôle est d’optimiser, de sécuriser et de garantir la fluidité des données pour les analystes et les scientifiques des données.
Data Lake
Un Data Lake (Lac de Données) est un endroit où est réuni un vaste ensemble de données dont la plupart sont dans leur état brut et non-structuré. Le Data Lake se distingue du Data Warehouse que nous allons définir dans un instant.
Data Mining
Le data mining consiste à détecter des patterns / des modèles à partir de l’analyse de vastes ensembles de données. Le data mining est l’art de mettre de l’intelligence dans les données, de créer des connexions entre données, de transformer les données innombrables du Big Data en informations exploitables, en « insights ».
(Big) Data Scientist
Un Data Scientist est une personne qui sait organiser des données structurées et non-structurées grâce à des compétences très pointues en statistiques, en mathématiques et en programmation. Il analyse les données pour y découvrir des schémas (patterns) et des informations à même d’améliorer la compréhension du business et d’en améliorer la performance.
Il est l’homme du Big Data. Il ne doit pas être confondu avec le Data Engineer, dont le rôle est de construire les infrastructures data et d’en assurer la maintenance.
Data Visualization
La Data Visualization est l’art de transformer des données brutes en informations grâce à des outils graphiques (graphes, diagrammes, courbes, tableaux…) organisés dans des tableaux de bord ou reportings. En un mot : l’art de mettre en image les données de l’entreprise pour y déceler plus facilement des enseignements et aider à la prise de décision.
Data Warehouse
Un Data Warehouse (entrepôt de données) est un lieu de stockage des données. A la différence du Data Lake (qui est une sorte de fourre-tout), le Data Warehouse est un lieu où les données sont organisées. Le Data Lake stocke de l’eau (comme un lac !), le Data Warehouse stocke des bouteilles d’eau entreprosées sur des rangées – pour reprendre une métaphore souvent utilisée.
Les données des Data Warehouses sont organisées pour en faciliter l’analyse et le reporting. Le Big Data a surtout affaire aux Data Warehouses Cloud (les Data Warehouses classiques étant associés aux systèmes classiques de management des données).
Données structurées
Les données structurées désignent des informations organisées selon un schéma ou un modèle préétabli, généralement stockées dans des bases de données relationnelles avec des colonnes et des lignes définies, comme des tableaux ou des SQL.
Données non structurées
Les données non structurées désignent des informations sans format ou organisation spécifique, comprenant des textes, des images, des vidéos et d’autres types de données qui ne rentrent pas facilement dans des tableaux traditionnels.
Données semi-structurées
Les données semi-strucutrées désignent des informations qui ne sont pas organisées dans un format prédéfini comme les données structurées, mais qui contiennent des éléments organisateurs tels que des tags ou des hiérarchies, typiques des fichiers JSON et XML.
ETL
ETL est un acronyme pour : Extract, Transform, Load. En français : Extraire, Transformer et Charger. L’ETL désigne le process d’extraction et de préparation des données. L’ETL est traditionnellement associé aux Data Warehouses, mais le process est aussi utilisé dans les systèmes Big Data.
Hadoop
Hadoop reste aujourd’hui encore la principale plateforme Big Data. Basé sur Java, le framework open source Hadoop est utilisé pour stocker et traiter des données en masse. Hadoop fait partie du projet Apache, qui est aussi à l’origine des framework Pig, Hive et Spark.
Intelligence artificielle
L’intelligence artificielle désigne l’intelligence des machines, par opposition avec l’intelligence humaine. On parle d’IA, ou d’AI – Artificial Intelligence. Le terme même d’intelligence artificielle est parfois contesté, ces détracteurs considérant l’intelligence comme une faculté indissociablement liée à une conscience – conscience que les machines n’ont pas.
Pour résumer, l’IA désigne la capacité pour une machine d’effectuer des tâches normalement réalisées par les humains et nécessitant des capacités dépassant le schème classique de la programmation : reconnaissance vocale, perception visuelle, prise de décision, prédiction, capacité d’apprentissage. Le machine learning est une sous-partie du l’intelligence artificielle.
Internet des objets (IoT, Internet of Things)
L’Internet des Objets fait référence à un réseau d’objets physiques intégrant des capteurs, des logiciels et d’autres technologies pour se connecter et échanger des données avec d’autres dispositifs et systèmes via Internet. Il englobe tout, des appareils ménagers connectés aux véhicules autonomes, en passant par le prêt-à-porter.
Machine Learning
Le Machine Learning est un ensemble de techniques et de technologies permettant à un système informatique d’apprendre, de s’ajuster et de s’améliorer grâce aux données ingérées par lui. Le machine learning est à la base des progrès de l’intelligence artificielle.
Modèles de langage
Un modèle de langage est un algorithme informatique entraîné pour comprendre, générer et travailler avec le langage humain, souvent en prédisant la probabilité de séquences de mots. Ces modèles sont essentiels pour des applications comme la traduction automatique, la génération de texte et les assistants vocaux.
Métadonnées
Une métadonnée est une donnée qui décrit une autre donnée. Par exemple, la date à laquelle une donnée a été enregistrée est une meta-donnée. Le lieu où a été prise une photo est un autre exemple de métadonnées. D’autres exemples ? La taille d’un fichier, l’auteur de la donnée…Les métadonnées décrivent le contexte des données.
NoSQL
NoSQL est un terme générique utilisé pour désigner toutes les bases de données construites en dehors du modèle classique relationnel. Il existe plusieurs types de bases de données NoSQL : les bases de données orientées documents, les bases de données orientées clés-valeurs, les bases de données orientées colonnes. Les bases NoSQL sont au cœur des projets BigData. Elles rendent possible la gestion d’énormes volumes de données non-structurées. Cassandra et MongoDB représentent deux exemples emblématiques de BDD NoSQL.
Nous arrivons au terme de cette introduction au Big Data. Cette présentation était modeste dans ses intentions, nous ne prétendons pas avoir épuisé le sujet – un sujet si vaste ! Si nous vous avons éclairés sur les principaux enjeux, cas d’usage et concepts du Big Data, nous avons atteint notre objectif !
R (et Python)
R & Python sont les deux principaux langages de programmation utilisés dans le Big Data. Python est plus simple à utiliser que R, plus accessible aux débutants. Quoi qu’il en soit, ces deux langages, par leur flexibilité et leur efficacité, sont très pratiques pour processer de gros data sets. R est un langage plus spécifique dans la mesure où il est surtout utilisé pour réaliser des analyses statistiques.
Open source, ces deux langages font l’objet d’améliorations continues de la part de leurs utilisateurs. De nouvelles bibliothèques sont régulièrement créées (par exemple ggplot2 pour la Data Visualization).
Requêtes (Queries)
Une requête est une question adressée à une base de données pour obtenir les réponses que l’on souhaite. Les requêtes peuvent être plus ou moins complexes, suivant la nature des interrogations. Une requête simple serait par exemple : « Donne-moi tous les contacts de sexe féminin ».
Une requête plus complexe serait : « Donne-moi tous les contacts féminins de 30 à 40 ans ayant acheté le produit X et dont le dernier achat remonte à moins de X jours ». On le voit, la complexité des requêtes se mesure au nombre de conditions voulues. Les requêtes (queries) utilisées en Big Data sont bien plus complexes que celles utilisées sur les bases de données relationnelles.
Streaming de données
Le streaming de données désigne un flux continu d’informations générées en temps réel, souvent traitées et analysées à la volée pour obtenir des insights ou réagir à des événements spécifiques.

Fondateur de Custup, Antoine Coubray anime l’équipe de consultants en Données Clients.